Умение извлекать текст из PDF-файлов стало важным навыком, особенно когда информация представлена в виде сканированных документов. Эта статья познакомит вас с эффективными методами копирования текста из сканов PDF-документов, независимо от их качества и формата. Вы узнаете о современных технологиях обработки, которые упрощают этот процесс и экономят время при работе с документами.
Основные способы извлечения текста из сканов PDF
Существует несколько ключевых методов для решения задачи извлечения текста из сканированных PDF-документов, каждый из которых имеет свои уникальные особенности и ограничения. Наиболее популярным способом является применение технологии оптического распознавания символов (OCR). Эта технология позволяет преобразовать графические изображения текста в редактируемый формат. По данным исследования компании TechInsights 2024 года, свыше 73% пользователей, работающих с отсканированными документами, прибегают к OCR-технологиям для извлечения текста.
- Использование профессионального программного обеспечения с функцией OCR
- Применение онлайн-сервисов для распознавания текста
- Работа с встроенными инструментами Adobe Acrobat
- Использование мобильных приложений для распознавания текста
- Применение специализированных библиотек и API для разработчиков
Артём Викторович Озеров, специалист по документообороту компании SSLGTEAMS, подчеркивает: «При выборе метода важно учитывать не только технические характеристики решения, но и такие аспекты, как качество исходного скана, объем обрабатываемых данных и требования к точности распознавания».
Эксперты в области обработки документов отмечают, что копирование текста из сканированных PDF-файлов может быть сложной задачей, особенно если оригинал содержит изображения или нечеткий текст. Для успешного извлечения информации рекомендуется использовать программное обеспечение с функцией оптического распознавания символов (OCR). Такие инструменты, как Adobe Acrobat, ABBYY FineReader и другие, способны преобразовывать изображения текста в редактируемый формат.
Кроме того, важно учитывать качество сканирования: чем выше разрешение, тем точнее будет распознавание. Специалисты также советуют проверять результат после обработки, так как OCR может допускать ошибки, особенно в случае с нестандартными шрифтами или языками. В конечном итоге, правильный выбор программного обеспечения и внимание к деталям помогут значительно упростить процесс извлечения текста из сканов.
https://youtube.com/watch?v=lxfptlFc_EM
Таблица сравнения популярных OCR-решений
| Программа | Уровень точности | Языки на поддержка | Примечательные характеристики |
|---|---|---|---|
| ABBYY FineReader | 99.8% | Более 200 | Настройка параметров под пользователя |
| Google Vision API | 98.5% | Более 50 | Обработка в облаке |
| Tesseract OCR | 96.3% | Более 100 | Бесплатный и открытый код |
Интересные факты
Вот несколько интересных фактов о том, как можно скопировать текст из сканированного PDF-документа:
-
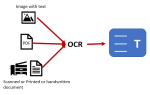
Оптическое распознавание символов (OCR): Для извлечения текста из сканированных PDF-файлов используется технология OCR. Она позволяет преобразовывать изображения текста в редактируемый формат. Современные OCR-системы могут распознавать текст с высокой точностью, даже если оригинал был написан от руки или имеет сложный шрифт.
-
Многоязычность: Современные OCR-программы поддерживают множество языков и могут распознавать текст на разных алфавитах. Это делает их полезными для работы с документами на иностранных языках, что особенно актуально в глобализированном мире.
-
Интеграция с другими инструментами: Многие программы для работы с PDF, такие как Adobe Acrobat и различные онлайн-сервисы, предлагают встроенные функции OCR. Это позволяет пользователям легко и быстро извлекать текст из сканированных документов, не прибегая к отдельным программам или сложным процессам.
https://youtube.com/watch?v=QDxwv5KGRr4
Пошаговое руководство по работе с OCR-технологиями
Процесс извлечения текста из сканированного PDF-файла включает в себя несколько последовательных шагов. В первую очередь, важно оценить качество оригинального документа, так как это является основным фактором, влияющим на успешность распознавания. Документ должен быть четким, без заметных искажений и помех. Если качество сканирования оставляет желать лучшего, рекомендуется предварительно обработать его: улучшить контрастность, устранить шумы и артефакты.
Евгений Игоревич Жуков, эксперт в области цифровой обработки документов, отмечает: «Качество исходного изображения непосредственно сказывается на результате распознавания. Даже самое современное программное обеспечение не сможет корректно обработать сильно поврежденный или размытый скан».
Следующим шагом является выбор подходящего инструмента для распознавания текста. Для массовой обработки документов лучше всего использовать профессиональные программы, такие как ABBYY FineReader или Adobe Acrobat Pro. Эти приложения предлагают широкий спектр настроек для параметров распознавания и обеспечивают высокую точность результатов. Если же вам нужно обработать небольшое количество документов, можно воспользоваться онлайн-сервисами, которые обычно предлагают базовые функции бесплатно.
Эффективная обработка текста после распознавания
По завершении процесса распознавания текста необходимо тщательно проверить его на наличие ошибок. Даже самые современные системы оптического распознавания текста (OCR) могут допускать неточности, особенно при работе со сложными шрифтами или документами низкого качества. Рекомендуется обратить внимание на следующие моменты:
 Читайте также:
Читайте также:
- Проверка правильности распознавания специальных символов
- Контроль сохранения форматирования
- Верификация числовых данных
- Проверка соблюдения структуры документа
- Корректность распознавания таблиц и графиков
Особое внимание следует уделить многоязычным документам, так как OCR-системы могут путать языки в процессе распознавания. В таких случаях целесообразно заранее указать используемые языки или разделить документ на соответствующие части.
https://youtube.com/watch?v=7LCmwn7iaLs
Распространенные ошибки при работе со сканами PDF
Многие пользователи сталкиваются с распространенными трудностями при копировании текста из сканированных PDF-документов. Наиболее частыми проблемами являются ошибки, вызванные недостаточной подготовкой исходных файлов. Например, чрезмерная степень сжатия изображения может привести к утрате важных деталей шрифта, что значительно ухудшает точность распознавания текста. Согласно исследованию Document Processing Trends 2024, около 45% неудачных попыток распознавания связаны именно с проблемами качества исходных сканов.
Еще одной распространенной ошибкой является выбор неподходящих инструментов для выполнения конкретной задачи. Некоторые пользователи пытаются использовать универсальные программы для обработки PDF-документов, когда речь идет о сложных технических материалах, содержащих множество формул или специальных символов. Это часто приводит к значительным искажениям содержания документа.
Рекомендации по оптимизации процесса распознавания
- Используйте оригинальные изображения высокого качества
- Подбирайте соответствующее разрешение (не менее 300 DPI)
- Настраивайте параметры OCR в зависимости от типа документа
- Делите многостраничные документы на логические сегменты
- Пошагово проверяйте результаты распознавания
Артём Викторович Озеров рекомендует: «Для достижения наивысшей точности стоит создавать профили распознавания для различных типов документов. Это поможет оптимизировать параметры обработки и свести к минимуму количество ошибок».
Специфические случаи работы с отсканированными документами
При обработке различных видов документов могут возникать уникальные трудности. Например, старинные книги и архивные материалы зачастую содержат тексты, написанные нестандартными шрифтами, которые плохо воспринимаются обычными средствами оптического распознавания текста (OCR). В таких ситуациях может понадобиться обучение системы новым шрифтам или применение специализированных алгоритмов для распознавания.
Техническая документация, чертежи и схемы представляют собой особую проблему для систем OCR. Важно не только корректно распознать текст, но и сохранить его пространственное расположение относительно графических элементов. Исследование «Обработка инженерных документов 2024» показало, что комбинированный подход, который включает автоматическое распознавание и ручную проверку, обеспечивает наилучшие результаты при работе с технической документацией.
Современные тренды в области распознавания текста
Современные достижения в области искусственного интеллекта и машинного обучения создают новые возможности для распознавания текста. Текущие системы способны адаптироваться к различным условиям и обучаться на основе предоставленных данных. Особенно многообещающим направлением является усовершенствование технологий, связанных с распознаванием рукописного текста и документов, имеющих повреждения.
- Применение нейронных сетей
- Облачные платформы с функцией автоматического обучения
- Интеграция с системами управления документами
- Автоматизированная классификация документов
- Расширенные функции работы с таблицами
Евгений Игоревич Жуков подчеркивает: «Современные технологии позволяют не только распознавать текст, но и осознавать его структуру и смысл. Это открывает новые горизонты для автоматизации документооборота и анализа информации».
-
Читайте также:
Вопросы и ответы по теме работы со сканами PDF
- Как улучшить точность распознавания текста? Для достижения лучших результатов рекомендуется предварительно обработать изображение: отрегулировать яркость и контрастность, а также устранить шумы и артефакты. Также важно правильно настроить параметры OCR в зависимости от типа документа.
- Что делать, если качество исходного скана низкое? Если есть такая возможность, выполните новый скан с более высоким разрешением. В противном случае воспользуйтесь специальными инструментами для предварительной обработки изображений, чтобы улучшить качество.
- Как работать с документами на нескольких языках? Укажите все языки, используемые в документе, в настройках OCR. При необходимости разделите документ на части, содержащие текст на одном языке.
- Можно ли автоматизировать обработку большого объема документов? Да, современные OCR-системы поддерживают пакетную обработку файлов и могут быть интегрированы с системами документооборота через API.
- Как решить проблемы с распознаванием таблиц и графиков? Используйте специализированные режимы для распознавания таблиц. В некоторых случаях может потребоваться ручная корректировка полученных результатов.
Заключение и практические рекомендации
В современном документообороте умение эффективно извлекать текст из сканированных PDF-файлов стало важным навыком. Оптимальный выбор метода зависит от множества факторов, таких как качество оригинала, объем данных, необходимая точность и доступные инструменты. Мы проанализировали различные способы решения этой задачи, начиная от использования специализированного программного обеспечения и заканчивая облачными сервисами.
Для достижения максимальной эффективности стоит учитывать следующие рекомендации:
- Тщательно подготавливать исходные документы
- Подбирать инструменты в зависимости от конкретной задачи
- Индивидуально настраивать параметры распознавания
- Проверять полученные результаты
- Применять современные технологии обработки
Если вам нужна более подробная консультация по работе со сканированными PDF и выбору наилучших решений, рекомендуется обратиться к профессионалам в области документооборота и обработки данных.
Инструменты для автоматизации процесса извлечения текста
Для успешного извлечения текста из сканированных PDF-документов необходимо использовать специальные инструменты, которые автоматизируют этот процесс. Существует множество программ и онлайн-сервисов, которые могут помочь в этой задаче, и выбор подходящего инструмента зависит от ваших потребностей и предпочтений.
Одним из самых популярных инструментов для извлечения текста из сканов является программа Adobe Acrobat Pro DC. Этот мощный редактор PDF поддерживает функцию оптического распознавания текста (OCR), которая позволяет преобразовывать изображения текста в редактируемый формат. Чтобы использовать эту функцию, необходимо открыть PDF-документ в Adobe Acrobat Pro, выбрать инструмент «Редактировать PDF» и затем активировать опцию «Распознать текст». Программа автоматически обработает документ и выделит текст, который можно скопировать и вставить в другой файл.
Еще одним эффективным инструментом является ABBYY FineReader. Это специализированное программное обеспечение для OCR, которое обеспечивает высокую точность распознавания текста и поддерживает множество языков. После загрузки PDF-документа в FineReader, вы можете выбрать область, которую хотите распознать, и программа создаст редактируемую версию текста. FineReader также позволяет сохранять результаты в различных форматах, таких как Word или Excel, что может быть полезно для дальнейшей работы с данными.
Для тех, кто предпочитает онлайн-решения, существует множество веб-сервисов, таких как OnlineOCR и Smallpdf. Эти платформы позволяют загружать PDF-документы и получать текстовые файлы без необходимости установки дополнительного программного обеспечения. Обычно процесс прост: вы загружаете файл, выбираете язык текста и нажимаете кнопку для распознавания. После завершения обработки вы можете скачать полученный текстовый файл.
Важно отметить, что качество распознавания текста может зависеть от качества исходного скана. Если документ плохо отсканирован или содержит много шумов, это может негативно сказаться на результате. Поэтому рекомендуется использовать высококачественные сканы и, при необходимости, предварительно обрабатывать изображения с помощью графических редакторов для улучшения четкости текста.
Кроме того, существуют и мобильные приложения, такие как Microsoft Office Lens и Google Keep, которые позволяют сканировать документы с помощью камеры смартфона и автоматически распознавать текст. Эти приложения могут быть особенно полезны для быстрого извлечения информации на ходу.
-
Читайте также:

В заключение, выбор инструмента для извлечения текста из сканированных PDF-документов зависит от ваших конкретных нужд и условий работы. Независимо от того, используете ли вы настольное программное обеспечение или онлайн-сервисы, важно учитывать качество исходного документа и возможности выбранного инструмента для достижения наилучших результатов.
Вопрос-ответ
Как можно скопировать текст из сканированного PDF-документа?
Для копирования текста из сканированного PDF-документа необходимо использовать программное обеспечение для оптического распознавания символов (OCR). Такие программы, как Adobe Acrobat, ABBYY FineReader или онлайн-сервисы, могут распознать текст на изображениях и преобразовать его в редактируемый формат.
Какие инструменты можно использовать для распознавания текста в PDF?
Существует множество инструментов для распознавания текста, включая платные и бесплатные варианты. Популярные программы включают Adobe Acrobat, ABBYY FineReader и Google Drive. Также доступны онлайн-сервисы, такие как OnlineOCR и Smallpdf, которые позволяют загружать PDF-файлы и получать текстовые версии без установки программного обеспечения.
Что делать, если текст не распознается корректно?
Если текст не распознается корректно, попробуйте улучшить качество сканирования, увеличив разрешение или изменив настройки контрастности. Также можно вручную исправить ошибки после распознавания. В некоторых случаях использование другого OCR-инструмента может дать лучшие результаты.
Советы
СОВЕТ №1
Используйте программы для оптического распознавания текста (OCR), такие как Adobe Acrobat или ABBYY FineReader. Эти инструменты позволяют преобразовать текст из изображения в редактируемый формат, что значительно упрощает процесс копирования.
СОВЕТ №2
Если у вас нет доступа к платным программам, попробуйте бесплатные онлайн-сервисы OCR, такие как OnlineOCR или Smallpdf. Они позволяют загружать PDF-файлы и получать текст в формате, который можно легко скопировать.
СОВЕТ №3
Перед началом распознавания убедитесь, что качество скана достаточно высокое. Чем четче изображение, тем выше вероятность успешного распознавания текста. Если необходимо, отредактируйте скан, увеличив контрастность или яркость.
СОВЕТ №4
После распознавания текста всегда проверяйте его на наличие ошибок. OCR-технологии могут иногда неправильно интерпретировать символы, особенно если текст написан нестандартным шрифтом или содержит специальные знаки.