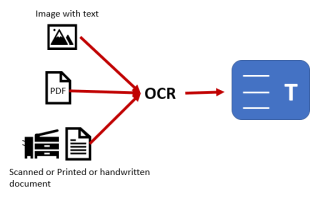
Технологии распознавания текста (OCR) становятся важным инструментом для управления документами. OCR преобразует печатные и рукописные тексты в цифровой формат, упрощая поиск, редактирование и хранение данных. В этой статье рассмотрим, что такое OCR, как он работает и какие преимущества предоставляет пользователям в бизнесе и образовании.
Что такое OCR и почему эта технология важна
Технология оптического распознавания символов (OCR) представляет собой программное решение, которое позволяет преобразовывать различные виды документов, включая сканированные бумажные материалы, PDF-файлы и изображения, в текст, который можно редактировать и искать. Процесс начинается с анализа структуры документа, в ходе которого система определяет области, содержащие текст, графику и другие элементы. Затем каждая буква проходит тщательный анализ с использованием матрицы точек, где каждая точка рассматривается как отдельный элемент. Современные алгоритмы OCR достигают точности распознавания до 99%, что делает эту технологию особенно актуальной в условиях растущих объемов цифровых данных.
Согласно последним исследованиям 2024 года, внедрение систем оптического распознавания текста позволило компаниям сократить время обработки документов в среднем на 73%. Особенно впечатляющие результаты наблюдаются в банковском секторе, где автоматизация документооборота привела к снижению числа ошибок при вводе данных на 85%. Артём Викторович Озеров, эксперт компании SSLGTEAMS, подчеркивает: «Современные OCR-решения – это не просто инструмент для распознавания текста, а целая экосистема, которая объединяет искусственный интеллект и машинное обучение для повышения точности обработки данных».
- Автоматизация рутинных задач
- Снижение числа человеческих ошибок
- Увеличение скорости обработки документов
- Снижение операционных расходов
Сравним традиционный подход к обработке документов с использованием OCR:
| Параметр | Традиционный метод | OCR |
|---|---|---|
| Скорость обработки | Низкая | Высокая |
| Точность | 75-80% | До 99% |
| Масштабируемость | Ограниченная | Неограниченная |
| Стоимость | Высокая | Низкая |
Эксперты в области информационных технологий отмечают, что распознавание текста (OCR) представляет собой важный инструмент для автоматизации обработки документов. Эта технология позволяет преобразовывать изображения текста, полученные с помощью сканеров или камер, в редактируемые текстовые форматы. Специалисты подчеркивают, что OCR значительно упрощает работу с большими объемами информации, позволяя быстро извлекать данные из бумажных носителей и переводить их в цифровой формат.
С развитием искусственного интеллекта и машинного обучения точность распознавания текста продолжает расти, что делает эту технологию еще более востребованной в различных сферах, от бизнеса до образования. Эксперты также отмечают, что современные системы OCR способны обрабатывать не только печатный текст, но и рукописные записи, что открывает новые возможности для анализа и хранения информации.

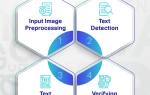
Как работает OCR и какие этапы включает процесс распознавания
Процесс оптического распознавания символов включает несколько основных этапов, каждый из которых имеет значительное значение для достижения высокой точности результата. В первую очередь осуществляется предварительная обработка изображения, которая включает в себя коррекцию наклона, устранение шумов и нормализацию контраста. На этом этапе особенно важны современные алгоритмы обработки изображений, позволяющие компенсировать различные недостатки исходного материала, такие как плохое освещение, искажения перспективы или механические повреждения документа. Евгений Игоревич Жуков, эксперт с 15-летним стажем работы в SSLGTEAMS, отмечает: «Качество предобработки составляет до 60% успеха всего процесса распознавания, именно поэтому мы уделяем этому этапу особое внимание в наших проектах».
После завершения предварительной обработки начинается этап сегментации, на котором система делит документ на логические блоки: текстовые области, таблицы, изображения и другие элементы. Здесь применяются сложные алгоритмы компьютерного зрения, способные различать различные типы контента. Затем происходит сам процесс распознавания символов, где каждый знак анализируется с помощью матрицы точек. Современные системы используют комбинированный подход, который сочетает классические методы анализа шрифтов с технологиями глубокого обучения. Это позволяет эффективно работать как со стандартными шрифтами, так и с рукописным текстом различных стилей и качества.
Заключительным этапом является постобработка, которая включает проверку контекста, исправление возможных ошибок и форматирование текста. Интересно, что согласно исследованию 2024 года, использование контекстного анализа повышает точность распознавания на 15-20% в случаях со сложными документами. Современные OCR-системы также способны сохранять оригинальное форматирование документа, включая таблицы, списки и стили текста, что значительно упрощает дальнейшую работу с полученным материалом.
| Аспект | Описание | Примеры использования |
|---|---|---|
| Что такое OCR? | Оптическое распознавание символов (Optical Character Recognition) – это технология, которая позволяет преобразовывать различные типы документов, такие как отсканированные бумажные документы, PDF-файлы или изображения, снятые цифровой камерой, в редактируемые и доступные для поиска данные. | Оцифровка старых книг, перевод рукописных заметок в электронный формат, извлечение данных из счетов и квитанций. |
| Как работает OCR? | Процесс включает несколько этапов: 1. Предварительная обработка изображения: улучшение качества изображения (удаление шумов, коррекция наклона). 2. Сегментация: разделение изображения на отдельные символы или слова. 3. Распознавание символов: сравнение каждого символа с базой данных известных символов или использование алгоритмов машинного обучения. 4. Постобработка: коррекция ошибок распознавания с помощью словарей и грамматических правил. | Сканирование документа, анализ его структуры, идентификация букв и цифр, формирование текстового файла. |
| Преимущества OCR | — Повышение эффективности: автоматизация ввода данных, сокращение ручного труда. — Улучшение доступности: возможность поиска по тексту, копирования и редактирования информации. — Экономия места: уменьшение необходимости в физическом хранении документов. — Улучшение безопасности: контроль доступа к цифровым документам. | Быстрый поиск информации в архивах, автоматическая обработка форм, создание электронных библиотек. |
| Недостатки и вызовы OCR | — Точность распознавания: может зависеть от качества исходного изображения, шрифта, языка. — Сложность обработки рукописного текста: значительно ниже точность по сравнению с печатным текстом. — Форматирование: сохранение исходного форматирования документа может быть сложной задачей. — Многоязычность: необходимость поддержки различных языков и алфавитов. | Ошибки в распознавании плохо читаемых документов, трудности с извлечением данных из сложных таблиц, необходимость ручной проверки результатов. |
| Виды OCR-систем | — Десктопные программы: устанавливаются на компьютер пользователя. — Облачные сервисы: доступ к OCR через интернет-браузер или API. — Встроенные OCR: интегрированы в другие приложения (например, в сканеры или мобильные приложения). | Adobe Acrobat Pro, ABBYY FineReader, Google Cloud Vision AI, Tesseract OCR (open-source). |
| Будущее OCR | — Улучшение точности: развитие алгоритмов машинного обучения и глубокого обучения. — Расширение возможностей: распознавание сложных структур (графиков, диаграмм), семантический анализ текста. — Интеграция с AI: использование OCR в более сложных системах искусственного интеллекта для автоматизации бизнес-процессов. | Автоматическое извлечение ключевой информации из юридических документов, создание интеллектуальных систем для анализа медицинских изображений, распознавание эмоций по тексту. |
Интересные факты
Вот несколько интересных фактов о распознавании текста (OCR):
-
История OCR: Первые системы распознавания текста появились в 1920-х годах. Одним из первых успешных примеров был проект, разработанный для распознавания печатных символов на бумаге, который использовал механические устройства. Однако настоящий прорыв произошел в 1970-х годах с развитием компьютерных технологий и алгоритмов обработки изображений.
-
Многоязычность и сложность: Современные OCR-системы могут распознавать текст на множестве языков и даже учитывать различные шрифты и стили написания. Некоторые системы способны распознавать рукописный текст, что значительно усложняет задачу из-за индивидуальных особенностей почерка.
-
Применение в различных сферах: OCR-технологии находят широкое применение в различных областях, включая банковское дело (распознавание чеков), здравоохранение (цифровка медицинских записей), юридическую сферу (сканирование документов) и даже в повседневной жизни (например, в приложениях для перевода текста с изображений). Это позволяет значительно ускорить обработку информации и уменьшить количество бумажной работы.

Преимущества использования OCR в бизнесе
Внедрение технологий оптического распознавания текста (OCR) открывает перед организациями новые горизонты для оптимизации рабочих процессов и повышения эффективности документооборота. Одним из ключевых преимуществ является значительная экономия времени на обработку документов. Согласно исследованию 2024 года, компании, которые внедрили OCR-системы, смогли сократить время на выполнение рутинных задач в среднем на 68%. Особенно ощутим эффект в юридической сфере, где работа с большими объемами документации требует высокой точности и внимательности к деталям.
Системы OCR обеспечивают надежную защиту данных благодаря возможности создания многоуровневой системы контроля доступа к информации. Кроме того, электронные версии документов легче защитить от несанкционированного доступа и копирования по сравнению с бумажными оригиналами. Артём Викторович Озеров подчеркивает: «Современные решения OCR позволяют не только создавать цифровые копии документов, но и формировать целую экосистему для их безопасного хранения и управления». Эта технология особенно ценна для компаний, работающих с большим количеством документов на различных языках, так как современные системы могут одновременно распознавать более 100 языков.
 Читайте также:
Читайте также:
- Автоматизация документооборота
- Формирование единой базы данных
- Быстрый поиск информации
- Интеграция с существующими IT-системами
Также стоит отметить, что системы можно масштабировать в зависимости от потребностей конкретного бизнеса. Независимо от размера компании — от небольшого предприятия до крупного холдинга — решения на базе OCR могут быть адаптированы под специфические задачи и объемы документооборота. По данным последних исследований, внедрение таких систем позволяет снизить операционные расходы на обработку документов в среднем на 47%.
Распространенные ошибки при использовании OCR и способы их предотвращения
Несмотря на высокую степень надежности современных систем оптического распознавания текста (OCR), существует ряд распространенных ошибок, которые могут значительно ухудшить качество распознавания. Одной из главных проблем является недостаточная подготовка исходных материалов: плохо освещенные документы, наличие посторонних объектов на изображении или неправильный угол сканирования могут снизить точность распознавания до 60%. Евгений Игоревич Жуков отмечает: «Многие пользователи не осознают, насколько важна правильная подготовка исходных файлов, полагая, что современные системы способны автоматически исправить любые недостатки».
Еще одной распространенной ошибкой является неверная настройка параметров распознавания. Например, выбор неправильного языка или типа документа может привести к серьезным искажениям текста. Исследование, проведенное в 2024 году, показало, что около 42% проблем с качеством распознавания связано именно с некорректными настройками системы. Также часто возникают ошибки при работе с многостраничными документами — неправильная нумерация страниц или потеря части содержимого из-за неверно установленных параметров обработки.
- Неправильная подготовка исходных документов
- Ошибочные настройки распознавания
- Отсутствие предварительной очистки изображений
- Игнорирование этапа проверки результатов
Чтобы избежать этих проблем, рекомендуется использовать специальные контрольные списки качества на каждом этапе обработки. Также важно регулярно проводить аудит настроек системы и обучать сотрудников правильным методам работы с технологиями OCR.

Практическое применение OCR в различных сферах
Технологии оптического распознавания текста (OCR) находят широкое применение в различных сферах человеческой деятельности, значительно повышая эффективность работы с документами. В банковском секторе системы OCR активно используются для автоматизации обработки платежных поручений, кредитных заявок и договоров. Согласно исследованию 2024 года, крупные финансовые учреждения, внедрившие эти технологии, смогли сократить время обработки клиентских документов на 75%. Особенно эффективно OCR функционирует в мобильном банкинге, где система может мгновенно распознавать реквизиты с фотографий карт или чеков.
В медицинской сфере технологии распознавания текста способствуют автоматизации работы с медицинской документацией, историей болезни пациентов и результатами анализов. Артём Викторович Озеров подчеркивает: «Внедрение OCR в медицинские учреждения не только ускорило обработку документов, но и значительно уменьшило количество медицинских ошибок, связанных с человеческим фактором». Современные системы способны распознавать даже сложные медицинские термины и специфические форматы записей, что особенно важно при работе с историей болезни пациентов.
- Автоматизация банковских операций
- Обработка медицинской документации
- Цифровизация архивов
- Автоматизация логистических процессов
В образовательной области технологии OCR активно используются для создания электронных библиотек, автоматизации проверки тестов и обработки студенческих работ. Особенно ценным становится применение этих систем при работе с историческими документами и архивами, где требуется максимально бережное отношение к оригиналам.
Вопросы и ответы по теме OCR
Давайте рассмотрим ключевые вопросы, которые возникают при использовании технологий оптического распознавания текста. Многие пользователи задаются вопросом о том, насколько эффективно OCR справляется с рукописным текстом. Современные системы могут достигать точности распознавания до 95% при обработке четко напечатанных текстов и около 85% для рукописных документов. Тем не менее, результаты сильно зависят от качества исходного материала и индивидуального стиля почерка. Евгений Игоревич Жуков рекомендует: «Чтобы добиться максимальной точности при работе с рукописными текстами, стоит использовать специализированные модули распознавания, обученные на соответствующих наборах данных».
- Как улучшить точность распознавания? — Используйте качественные исходные материалы, правильно настраивайте параметры системы и проводите предварительную обработку изображений.
- Можно ли интегрировать OCR с уже существующими IT-системами? — Да, современные решения поддерживают API-интеграцию с большинством популярных информационных систем.
- Как OCR работает с многоязычными документами? — Современные системы способны автоматически определять язык текста и переключаться между различными языками в одном документе.
- Что делать с документами, содержащими таблицы? — Используйте специальные режимы распознавания, которые сохраняют структуру таблиц и форматирование данных.
- Как обеспечить безопасность обрабатываемых документов? — Применяйте многоуровневую систему защиты, включая шифрование данных и контроль доступа.
Следует отметить, что эффективность применения OCR напрямую зависит от правильного выбора решения для конкретных задач и корректной настройки системы.
-
Читайте также:

Если вы хотите получить более подробную консультацию по внедрению OCR-систем в вашем бизнесе, рекомендуем обратиться к специалистам компании SSLGTEAMS. Они помогут подобрать оптимальное решение, учитывающее особенности вашей деятельности и объемы документооборота.
Будущее технологий OCR: тренды и прогнозы
Технологии оптического распознавания символов (OCR) продолжают развиваться с каждым годом, и их будущее обещает быть захватывающим. С учетом стремительного прогресса в области искусственного интеллекта и машинного обучения, можно выделить несколько ключевых трендов, которые будут определять развитие OCR в ближайшие годы.
Во-первых, интеграция OCR с искусственным интеллектом и глубоким обучением. Современные алгоритмы машинного обучения позволяют значительно повысить точность распознавания текста, особенно в сложных условиях, таких как низкое качество изображений или нестандартные шрифты. Это открывает новые возможности для применения OCR в различных сферах, включая медицинскую диагностику, юридические услуги и архивирование документов.
Во-вторых, рост популярности мобильных приложений с функциями OCR. С увеличением использования смартфонов и планшетов, разработчики создают все больше приложений, которые позволяют пользователям сканировать и распознавать текст на ходу. Это делает технологии OCR более доступными для широкой аудитории и способствует их внедрению в повседневную жизнь.
Третий тренд связан с улучшением обработки многоязычного текста. В глобализированном мире, где взаимодействие между культурами и языками становится все более распространенным, OCR-технологии должны адаптироваться к различным языковым системам. Это включает в себя не только распознавание текстов на разных языках, но и учет особенностей, таких как алфавиты, иероглифы и специальные символы.
Четвертым важным направлением является автоматизация процессов обработки документов. OCR уже активно используется для автоматизации рутинных задач, таких как ввод данных и архивирование. В будущем можно ожидать, что технологии будут интегрированы с системами управления документами и бизнес-процессами, что позволит значительно сократить время и затраты на обработку информации.
Наконец, стоит отметить важность обеспечения безопасности и конфиденциальности данных. С увеличением объемов обрабатываемой информации, особенно в таких чувствительных областях, как медицина и финансы, разработчики должны уделять особое внимание защите данных. Это может включать в себя использование шифрования, а также разработку алгоритмов, которые обеспечивают безопасность распознаваемой информации.
В заключение, будущее технологий OCR выглядит многообещающим. С учетом текущих трендов и прогнозов, можно ожидать, что OCR станет неотъемлемой частью множества процессов в различных отраслях, улучшая эффективность и доступность информации для пользователей по всему миру.
Вопрос-ответ
Что такое OCR в антиплагиате?
«Антиплагиат» должен проверять на заимствования именно тот текст, который видит человек. Для этого идеально подходят средства OCR (Optical Character Recognition – оптическое распознавание символов), которые позволяют получать текст из изображений текста (сканов, фотографий, скриншотов).
-
Читайте также:
Что такое OCR простыми словами?
Оптическое распознавание символов (OCR) – это процесс преобразования изображения текста в машиночитаемый текстовый формат. Например, при сканировании бланка или квитанции компьютер сохраняет скан в виде файла изображения.
В чем разница между OCR и PDF?
Оптическое распознавание символов (OCR) — это технология, которая преобразует печатные документы в файлы цифровых изображений. Это цифровое копировальное устройство, которое автоматически преобразует отсканированные документы в машиночитаемые PDF-файлы, которые можно редактировать и делиться ими.
Что значит проверить с OCR?
Оптическое распознавание символов (OCR), в частности, — это технология компьютерного зрения, которая может использоваться для обнаружения и извлечения текста. Модели OCR обучены распознавать текст в различных форматах и преобразовывать его в редактируемые данные, доступные для поиска.
Советы
СОВЕТ №1
Изучите различные OCR-программы и их возможности. Сравните функционал, точность распознавания и поддержку языков, чтобы выбрать наиболее подходящее решение для ваших нужд.
СОВЕТ №2
Обратите внимание на качество исходного изображения. Чем четче и качественнее будет скан или фотография текста, тем выше вероятность точного распознавания. Используйте хорошее освещение и избегайте искажений.
СОВЕТ №3
Попробуйте использовать OCR в сочетании с другими инструментами. Например, после распознавания текста проверьте его на наличие ошибок с помощью текстового редактора или специализированного программного обеспечения для коррекции.
СОВЕТ №4
Не забывайте о конфиденциальности данных. Если вы работаете с чувствительной информацией, выбирайте OCR-сервисы, которые обеспечивают защиту данных и не сохраняют загруженные документы на своих серверах.
Технологии оптического распознавания символов (OCR) продолжают развиваться с каждым годом, и их будущее обещает быть захватывающим. С учетом стремительного прогресса в области искусственного интеллекта и машинного обучения, можно выделить несколько ключевых трендов, которые будут определять развитие OCR в ближайшие годы.
Во-первых, интеграция OCR с искусственным интеллектом и глубоким обучением. Современные алгоритмы машинного обучения позволяют значительно повысить точность распознавания текста, особенно в сложных условиях, таких как низкое качество изображений или нестандартные шрифты. Это открывает новые возможности для применения OCR в различных сферах, включая медицинскую диагностику, юридические услуги и архивирование документов.
-
Читайте также:

Во-вторых, рост популярности мобильных приложений с функциями OCR. С увеличением использования смартфонов и планшетов, разработчики создают все больше приложений, которые позволяют пользователям сканировать и распознавать текст на ходу. Это делает технологии OCR более доступными для широкой аудитории и способствует их внедрению в повседневную жизнь.
Третий тренд связан с улучшением обработки многоязычного текста. В глобализированном мире, где взаимодействие между культурами и языками становится все более распространенным, OCR-технологии должны адаптироваться к различным языковым системам. Это включает в себя не только распознавание текстов на разных языках, но и учет особенностей, таких как алфавиты, иероглифы и специальные символы.
Четвертым важным направлением является автоматизация процессов обработки документов. OCR уже активно используется для автоматизации рутинных задач, таких как ввод данных и архивирование. В будущем можно ожидать, что технологии будут интегрированы с системами управления документами и бизнес-процессами, что позволит значительно сократить время и затраты на обработку информации.
Наконец, стоит отметить важность обеспечения безопасности и конфиденциальности данных. С увеличением объемов обрабатываемой информации, особенно в таких чувствительных областях, как медицина и финансы, разработчики должны уделять особое внимание защите данных. Это может включать в себя использование шифрования, а также разработку алгоритмов, которые обеспечивают безопасность распознаваемой информации.
В заключение, будущее технологий OCR выглядит многообещающим. С учетом текущих трендов и прогнозов, можно ожидать, что OCR станет неотъемлемой частью множества процессов в различных отраслях, улучшая эффективность и доступность информации для пользователей по всему миру.