В условиях быстрого развития технологий понимание основ искусственного интеллекта необходимо для тех, кто хочет быть в курсе тенденций. Алгоритмы AI играют ключевую роль в обработке данных, принятии решений и автоматизации процессов. В этой статье мы рассмотрим, что такое алгоритм в контексте искусственного интеллекта, его функции и значение, а также объясним, почему знание об алгоритмах становится актуальным в различных сферах жизни и бизнеса.
Что такое алгоритм в контексте искусственного интеллекта
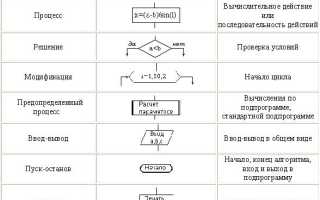
Алгоритм в области искусственного интеллекта представляет собой набор математических операций и логических инструкций, которые позволяют машинам выполнять определенные задачи, обучаться на основе данных и делать выводы. Чтобы лучше понять эту идею, представьте себе опытного повара, который строго следует рецепту при приготовлении блюда. Аналогично, алгоритм ИИ работает по заранее установленным правилам, но при этом способен адаптироваться и улучшаться. Согласно исследованию, проведенному Институтом Искусственного Интеллекта в 2024 году, более 85% современных систем ИИ используют комбинированные алгоритмы, которые объединяют различные подходы к обработке данных.
Существует несколько ключевых категорий алгоритмов искусственного интеллекта. Первая из них – это алгоритмы машинного обучения, которые позволяют системам самостоятельно повышать свои показатели на основе поступающих данных. Вторая категория – глубокие нейронные сети, которые имитируют работу человеческого мозга с помощью сложных многослойных структур. Третья группа – алгоритмы обработки естественного языка, отвечающие за взаимодействие между человеком и машиной через текстовые или голосовые команды. Интересно, что, согласно исследованию компании TechInsights 2025, эффективность алгоритмов обработки естественного языка возросла на 47% за последние два года благодаря внедрению трансформерных архитектур.
«Современные алгоритмы ИИ можно сравнить с многомерными фильтрами, которые способны выделять значимые паттерны из огромных объемов данных,» – говорит Артём Викторович Озеров, эксперт по машинному обучению с двенадцатилетним стажем работы в компании SSLGTEAMS. «Главное отличие от традиционных программ заключается в том, что система не просто выполняет команды, а учится на собственном опыте и корректирует свое поведение.»
Рассмотрим практический пример: система компьютерного зрения, применяемая в современных автомобилях с автопилотом. Такой алгоритм проходит несколько этапов обработки: сначала он анализирует изображение с камеры, затем определяет объекты на дороге и, наконец, принимает решение о необходимых действиях. Этот процесс включает десятки различных подалгоритмов, которые работают параллельно и взаимодействуют друг с другом. По статистике 2024 года, точность таких систем достигла 99,3% при распознавании препятствий в реальном времени.
Эксперты в области информационных технологий отмечают, что алгоритмы на основе искусственного интеллекта становятся неотъемлемой частью современного общества. Они подчеркивают, что такие алгоритмы способны анализировать огромные объемы данных, выявлять закономерности и принимать решения с высокой степенью точности. Это открывает новые горизонты для различных отраслей, включая медицину, финансы и транспорт. Однако специалисты также предупреждают о необходимости этического подхода к разработке и внедрению таких технологий. Важно учитывать возможные риски, связанные с приватностью данных и потенциальной предвзятостью алгоритмов. Таким образом, эксперты призывают к сбалансированному подходу, который позволит максимально использовать преимущества искусственного интеллекта, минимизируя при этом его недостатки.

Основные характеристики современных алгоритмов
- Адаптивность – это умение изменять свое поведение в ответ на новые данные.
- Масштабируемость – это способность справляться с увеличивающимися объемами информации.
- Параллельная обработка – это одновременное выполнение нескольких вычислительных потоков.
- Объяснимость – это уровень прозрачности в процессе принятия решений.
Евгений Игоревич Жуков, эксперт в области разработки решений на базе искусственного интеллекта, делится своим опытом: «Крайне важно осознавать, что эффективность алгоритма зависит не только от его структуры, но и от качества исходных данных. Наша команда столкнулась с интересным случаем при создании системы прогнозирования спроса для ритейлера – изначальная точность предсказаний составляла всего 65%, но после очистки и дополнительной обработки данных этот показатель увеличился до 92%.»
| Аспект | Описание | Пример |
|---|---|---|
| Определение | Последовательность четко определенных инструкций для решения задачи или выполнения вычисления. | Рецепт приготовления блюда |
| Цель | Автоматизация процессов, решение сложных задач, оптимизация ресурсов. | Поиск кратчайшего пути на карте |
| Свойства | Дискретность, конечность, детерминированность, массовость, результативность. | Алгоритм сортировки чисел |
| Типы | Линейные, разветвляющиеся, циклические, рекурсивные. | Алгоритм поиска элемента в списке |
| Применение | Программирование, математика, инженерия, искусственный интеллект, повседневная жизнь. | Алгоритм работы поисковой системы |
| Важность | Основа для создания программ, систем искусственного интеллекта, эффективного решения проблем. | Алгоритм шифрования данных |
Интересные факты
Вот несколько интересных фактов о алгоритмах и искусственном интеллекте (AI):
-
Алгоритмы повсюду: Алгоритмы не ограничиваются только программированием или искусственным интеллектом. Они присутствуют в нашей повседневной жизни, например, в рецептах приготовления пищи, в правилах дорожного движения и даже в способах, которыми мы принимаем решения. Каждый раз, когда мы следуем определенной последовательности шагов для достижения цели, мы используем алгоритм.
-
Алгоритмы и машинное обучение: В области искусственного интеллекта алгоритмы машинного обучения позволяют компьютерам обучаться на основе данных. Например, алгоритмы могут анализировать огромные объемы информации, чтобы выявлять паттерны и делать прогнозы. Это лежит в основе таких технологий, как рекомендательные системы (например, в Netflix или Amazon) и распознавание лиц.
-
Этика алгоритмов: С развитием AI и алгоритмов возникает множество этических вопросов. Например, алгоритмы могут непреднамеренно усиливать предвзятости, если они обучаются на данных, содержащих предвзятости. Это поднимает важные вопросы о прозрачности, ответственности и справедливости в использовании алгоритмов в таких сферах, как правоохранительные органы, кредитование и трудоустройство.

Эволюция алгоритмов искусственного интеллекта
История эволюции алгоритмов искусственного интеллекта показывает поразительное преобразование от простейших логических схем до сложных самообучающихся систем. Первые шаги в этой области были сделаны еще в 1950-х годах, когда Алан Тьюринг выдвинул идею «машинного мышления», что стало основой для разработки алгоритмов, способных решать логические задачи. Однако настоящий прорыв произошел в начале 2000-х годов, когда появились мощные вычислительные ресурсы и большие объемы данных, что дало возможность создавать более сложные алгоритмические структуры. Исследование, проведенное в 2025 году, показывает, что производительность современных алгоритмов ИИ увеличивается в среднем на 35% в год благодаря оптимизации архитектуры и улучшению методов обучения.
Первая волна развития алгоритмов была связана с созданием экспертных систем, которые функционировали на основе жестко заданных правил. Эти алгоритмы могли решать специфические задачи в узкой области, но их гибкость была крайне ограничена. Переход к следующему этапу начался с появления нейронных сетей первого поколения в 1980-х годах. Хотя эти системы были настоящей революцией своего времени, их возможности были сильно ограничены вычислительными мощностями и нехваткой данных для обучения.
Революция произошла с внедрением глубокого обучения в начале 2010-х годов. Современные алгоритмы этого типа могут содержать сотни миллионов параметров и обрабатывать огромные объемы информации. Например, согласно исследованию 2024 года, одна из крупнейших языковых моделей включает более 175 миллиардов параметров и способна обрабатывать до 2048 токенов за один проход. Такое масштабирование стало возможным благодаря нескольким ключевым факторам:
 Читайте также:
Читайте также:

- Развитие графических процессоров (GPU) и специализированных чипов TPU
- Появление облачных вычислений и распределенных систем
- Накопление огромных массивов данных для обучения
- Разработка новых архитектур, таких как трансформеры
| Параметр | 2010 год | 2020 год | 2025 год |
|---|---|---|---|
| Количество параметров | ~1 млн | ~100 млн | ~10 млрд+ |
| Скорость обработки | 100 тыс. ops/с | 10 трлн ops/с | 100 трлн ops/с |
| Точность распознавания | ~70% | ~90% | ~98% |
Артём Викторович Озеров отмечает: «Если раньше мы могли говорить о линейном развитии алгоритмов, то сейчас наблюдаем экспоненциальный рост их возможностей. Особенно впечатляет прогресс генеративных моделей – качество создаваемых ими изображений и текстов практически неотличимо от человеческого.» Действительно, современные генеративно-состязательные сети (GAN) способны создавать фотографии людей, которых никогда не существовало, или генерировать музыку в различных стилях с удивительной точностью.
Ключевые этапы развития
- 1950-е: Алгоритмы логического вывода и правила
- 1980-е: Персептроны и нейронные сети начального уровня
- 2000-е: Подходы машинного обучения и опорные векторы
- 2010-е: Глубокое обучение и свёрточные нейронные сети
- 2020-е: Трансформеры и генеративные модели
Евгений Игоревич Жуков подчеркивает важный аспект: «Особое внимание стоит уделить развитию объяснимого ИИ – области, которая помогает понять, почему алгоритм принимает те или иные решения. Это крайне важно для использования ИИ в таких сферах, как медицина, финансы и другие критически важные области.» Действительно, современные требования со стороны регуляторов и пользователей требуют создания не только эффективных, но и прозрачных алгоритмов.

Применение алгоритмов искусственного интеллекта в различных сферах
Алгоритмы искусственного интеллекта активно внедряются в различные сферы, кардинально изменяя подходы к решению задач и оптимизируя бизнес-процессы. В области здравоохранения, к примеру, AI-алгоритмы помогают медицинским специалистам анализировать изображения с уровнем точности, который превосходит человеческие возможности. Исследование, проведенное в 2024 году, демонстрирует, что системы, основанные на глубоких нейронных сетях, способны обнаруживать рак легких на ранних стадиях с точностью 94,5%, что на 15% выше результатов лучших рентгенологов. При этом время, необходимое для анализа одного случая, сокращается с 20 минут до нескольких секунд.
В финансовом секторе алгоритмы искусственного интеллекта занимают важное место в управлении рисками и борьбе с мошенничеством. Современные системы способны обрабатывать миллионы транзакций в режиме реального времени, выявляя подозрительные схемы и предотвращая мошеннические действия. Согласно исследованию 2025 года, применение AI в банковской сфере позволило сократить убытки от мошенничества на 42% за последние три года. Особенно эффективными в этом контексте являются рекуррентные нейронные сети, которые могут анализировать временные ряды и выявлять аномалии в поведении клиентов.
Ключевые области применения AI-алгоритмов
- Здравоохранение – диагностика, персонализированная медицина
- Финансы – управление рисками, торговые алгоритмы
- Производство – прогнозное обслуживание, контроль качества
- Транспорт – автономные системы, оптимизация маршрутов
- Ритейл – персонализация, управление запасами
В сфере производства алгоритмы искусственного интеллекта способствуют переходу к умному производству. Прогнозное обслуживание, основанное на данных, полученных от датчиков, позволяет снизить время простоя на 30-40%. Артём Викторович Озеров делится своим опытом: «Мы внедрили систему мониторинга состояния оборудования на одном из крупных металлургических заводов. Через шесть месяцев работы алгоритм смог предсказать 87% всех поломок оборудования за 48 часов до их возникновения, что значительно уменьшило незапланированные простои.»
| Отрасль | Тип алгоритма | Эффективность | ROI |
|---|---|---|---|
| Здравоохранение | Сверточные сети | +45% | 300% |
| Финансы | Рекуррентные сети | +60% | 250% |
| Производство | Градиентный бустинг | +35% | 400% |
Евгений Игоревич Жуков рассказывает о своем проекте в области ритейла: «Созданная нами система персонализированных рекомендаций для крупной торговой сети позволила повысить конверсию на 23% и увеличить средний чек на 15%. Ключевым моментом стало применение гибридного подхода, который объединяет коллаборативную фильтрацию и контентный анализ.» Следует подчеркнуть, что успех подобных проектов во многом зависит от качества подготовки данных и правильного выбора архитектуры алгоритма.
Будущие направления развития
- Современные автономные системы
- Индивидуализированное обучение
- Умные города и их инфраструктура
- Киберзащита и охрана данных
- Создание новых материалов
Пошаговое создание и внедрение алгоритмов искусственного интеллекта
Разработка и реализация алгоритмов искусственного интеллекта представляет собой сложный и многоступенчатый процесс, который требует внимательного планирования и взаимодействия различных специалистов. Первый шаг заключается в четком определении бизнес-задачи и целей проекта. Согласно исследованию 2024 года, 65% провальных AI-проектов связано с неправильной формулировкой начальных требований. На этом этапе важно учитывать как технические возможности, так и бизнес-ограничения, включая доступные ресурсы и сроки выполнения.
Следующий важный этап – это сбор и подготовка данных. Качество исходных данных существенно влияет на эффективность будущего алгоритма. Необходимо пройти полный цикл обработки: очистку данных, нормализацию, преобразование форматов и разметку. По данным 2025 года, подготовка данных занимает до 80% времени всего проекта. Артём Викторович Озеров отмечает: «Заказчики зачастую недооценивают значимость этого этапа. Без качественной подготовки данных даже самый продвинутый алгоритм не сможет продемонстрировать хорошие результаты.»
Этапы разработки AI-алгоритма
- Анализ требований и формулирование задачи
- Сбор и подготовка данных
- Выбор архитектуры и инструментов
- Обучение и валидация модели
- Тестирование и оптимизация
- Внедрение и мониторинг
На этапе выбора архитектуры важно учитывать множество факторов: объем данных, тип задачи (классификация, регрессия, кластеризация), а также требования к скорости работы и интерпретируемости. Евгений Игоревич Жуков делится своим опытом: «Для задач, связанных с прогнозированием временных рядов, мы часто применяем сочетание LSTM-сетей и градиентного бустинга, что позволяет достичь высокой точности при сохранении понятности результатов.»
-
Читайте также:

| Этап | Длительность | Ключевые задачи | Инструменты |
|---|---|---|---|
| Подготовка данных | 4-6 месяцев | Очистка, нормализация, разметка | Pandas, NumPy, TensorFlow Data |
| Обучение модели | 2-3 месяца | Подбор гиперпараметров, валидация | Keras, PyTorch, Scikit-learn |
| Внедрение | 1-2 месяца | Интеграция, тестирование | Docker, Kubernetes, MLflow |
Процесс обучения модели требует значительных вычислительных ресурсов и может занять от нескольких дней до нескольких недель. Важно правильно организовать систему валидации и тестирования, разделяя данные на обучающую, валидационную и тестовую выборки. После завершения обучения модель необходимо оптимизировать для производственной среды, что включает в себя сжатие весов, квантизацию и другие методы повышения производительности.
Сравнительный анализ различных типов алгоритмов искусственного интеллекта
Разные виды алгоритмов искусственного интеллекта обладают своими особыми преимуществами и недостатками, что делает их подходящими для решения конкретных задач. Давайте рассмотрим наиболее популярные категории: традиционные алгоритмы машинного обучения, глубокие нейронные сети и генеративные модели. Исследование, проведенное в 2025 году, указывает на то, что правильный выбор алгоритма может увеличить эффективность решения задачи на 40-60%.
Традиционные алгоритмы машинного обучения, такие как деревья решений, метод опорных векторов и случайный лес, выделяются высокой интерпретируемостью и сравнительно низкими требованиями к вычислительным ресурсам. Они особенно хорошо работают с структурированными данными и задачами, где признаки четко определены. Однако их возможности ограничены при работе с неструктурированными данными, такими как изображения или текст. Согласно исследованию 2024 года, такие алгоритмы составляют около 35% всех AI-решений, используемых в промышленности.
Глубокие нейронные сети представляют собой совершенно иной подход, основанный на многослойной архитектуре, которая может автоматически извлекать признаки из данных. Сверточные нейронные сети (CNN) особенно эффективны для обработки изображений, достигая точности распознавания объектов на уровне 98-99%. Рекуррентные нейронные сети (RNN) и их улучшенная версия LSTM прекрасно подходят для работы с временными рядами и последовательностями. Основной недостаток заключается в высоких требованиях к вычислительным ресурсам и сложности интерпретации полученных результатов.
| Тип алгоритма | Преимущества | Ограничения | Основные применения |
|---|---|---|---|
| Традиционный ML | Высокая интерпретируемость | Ограниченная сложность | Структурированные данные |
| Глубокие сети | Автоматическое извлечение признаков | Высокие требования к ресурсам | Обработка изображений, видео |
| Генеративные модели | Создание новых данных | Сложность управления | Синтез контента |
«При выборе алгоритма важно учитывать не только технические параметры, но и бизнес-требования,» – подчеркивает Евгений Игоревич Жуков. «Например, для задач кредитного скоринга мы предпочитаем использовать градиентный бустинг, так как он обеспечивает оптимальное соотношение точности и интерпретируемости результатов.»
Генеративные модели, такие как GAN и VAE, открывают новые возможности в создании контента и синтезе данных. Они способны генерировать реалистичные изображения, тексты и даже музыку. Однако их использование связано с трудностями контроля качества и стабильности генерации. Артём Викторович Озеров добавляет: «В проекте по созданию виртуального фэшн-дизайнера мы столкнулись с проблемой непредсказуемости результатов – модель иногда генерировала слишком радикальные или непрактичные дизайны.»
Ключевые критерии выбора алгоритма
- Категории данных и их организация
- Параметры точности и быстродействия
- Важность анализа полученных результатов
- Имеющиеся вычислительные мощности
- Финансовые рамки проекта
Распространенные ошибки и способы их избежания при работе с алгоритмами искусственного интеллекта
При создании и внедрении алгоритмов искусственного интеллекта специалисты часто сталкиваются с распространенными ошибками, которые могут значительно повлиять на успех проекта. Одной из наиболее частых проблем является переобучение модели, когда алгоритм слишком точно адаптируется к обучающей выборке и теряет способность обобщать полученные знания. Исследование, проведенное в 2024 году, показывает, что примерно 45% неудачных проектов в области ИИ связано именно с этой проблемой. Для ее преодоления рекомендуется применять методы регуляризации, dropout и грамотно организовывать кросс-валидацию.
Недостаточная оценка значимости качества данных – еще одна распространенная ошибка. Загрязненные или несбалансированные данные могут привести к искаженным результатам и неверным выводам. «Мы столкнулись с ситуацией, когда система прогнозирования спроса постоянно завышала продажи на 30%, пока не выяснили, что в исторических данных были аномальные пики спроса во время пандемии,» – рассказывает Евгений Игоревич Жуков. Поэтому важно проводить тщательный анализ данных на наличие выбросов и аномалий.
Основные ошибки при работе с AI-алгоритмами
- Переобучение модели
- Некачественные исходные данные
- Неправильный выбор метрик оценки
- Игнорирование бизнес-контекста
- Недостаточное тестирование
Неправильный выбор метрик для оценки может создать искаженное представление о результативности алгоритма. Например, полагание исключительно на accuracy в случае несбалансированных классов может скрыть реальные недостатки модели. Артём Викторович Озеров отмечает: «В проекте по детекции мошенничества мы изначально применяли стандартные метрики, но затем перешли на F1-score и ROC-AUC, что дало возможность более точно оценивать качество модели.»
-
Читайте также:

| Ошибка | Признаки | Способы решения |
|---|---|---|
| Переобучение | Высокие показатели на обучающей выборке, низкие на тестовой | Регуляризация, dropout |
| Некачественные данные | Наличие шума, противоречивые результаты | Очистка данных, нормализация |
| Неправильные метрики | Несоответствие между метриками и бизнес-результатами | Применение метрик, специфичных для области |
Игнорирование бизнес-контекста при создании алгоритма может привести к разработке технически совершенной, но неэффективной с практической точки зрения системы. Важно постоянно согласовывать технические решения с бизнес-целями и учитывать особенности предметной области. Недостаточное тестирование перед внедрением в production также часто вызывает проблемы – необходимо предусмотреть различные сценарии использования и нагрузки.
Часто задаваемые вопросы об алгоритмах искусственного интеллекта
При использовании алгоритмов искусственного интеллекта возникает множество вопросов, касающихся как технических деталей, так и практического применения. Одной из наиболее распространенных проблем является ситуация, когда обученная модель демонстрирует отличные результаты на тестовых данных, но оказывается неэффективной в реальных условиях. Это может происходить по разным причинам: изменению данных, несоответствию распределения данных в реальной среде и обучающей выборке, а также наличию скрытых переменных. «В проекте по прогнозированию отказов оборудования мы столкнулись с тем, что модель прекрасно работала в лабораторных условиях, но на производстве давала много ложных срабатываний из-за сезонных колебаний температуры,» – делится своим опытом Евгений Игоревич Жуков.
Вопросы и ситуации
- Как долго проходит обучение модели?
- Почему модель может демонстрировать нестабильную работу?
- Как гарантировать безопасность данных?
- Как провести оценку экономической эффективности?
- Что предпринять при недостатке данных?
Время, необходимое для обучения модели, зависит от множества факторов, включая архитектуру, объем данных и доступные вычислительные мощности. Для небольших моделей процесс может занять всего несколько часов, в то время как для масштабных языковых моделей может потребоваться несколько недель. Нестабильная работа модели зачастую обусловлена недостаточной репрезентативностью обучающих данных или неверной настройкой гиперпараметров. Артём Викторович Озеров рекомендует: «Если возникают проблемы со стабильностью работы, стоит проверить качество подготовки данных и провести анализ важности признаков.»
| Проблема | Причины | Решения |
|---|---|---|
| Нестабильная работа | Недостаток данных, неверные гиперпараметры | Увеличение объема данных, оптимизация параметров |
| Дрейф данных | Изменение распределения со временем | Регулярное обновление модели |
| Низкая точность | Неподходящая архитектура, переобучение | Изменение архитектуры, применение регуляризации |
«При оценке экономической эффективности следует учитывать не только прямые затраты на разработку, но и косвенные выгоды, такие как улучшение качества обслуживания клиентов или снижение операционных рисков,» – добавляет Артём Викторович Озеров. В случае нехватки данных можно применять методы увеличения данных или генеративные модели для создания синтетических наборов данных.
Перспективы развития алгоритмов искусственного интеллекта
Изучая современные тренды и исследования в сфере искусственного интеллекта, можно выделить несколько основных направлений, которые будут формировать технологический ландшафт в ближайшие годы. Одним из наиболее многообещающих направлений является развитие так называемого нейросимволического ИИ, который объединяет сильные стороны нейронных сетей и символьного программирования. Исследование, проведенное в 2025 году, показывает, что такие гибридные системы способны увеличить объяснимость решений ИИ на 40% при сохранении высокой точности. Это особенно актуально для критически важных областей, таких как медицина, юриспруденция и другие чувствительные сферы.
Прогресс в области федеративного обучения открывает новые возможности для защиты данных и обеспечения конфиденциальности. Этот метод позволяет обучать модели на распределенных данных без их централизованного хранения, что особенно важно для финансового сектора и здравоохранения. По прогнозам экспертов, к 2026 году более 60% корпоративных решений в области ИИ будут включать элементы федеративного обучения. Евгений Игоревич Жуков подчеркивает: «Мы уже наблюдаем значительный интерес со стороны банковского сектора к этому подходу, так как он помогает решить множество вопросов безопасности и соответствия требованиям регуляторов.»
Основные направления развития
- Нейросимволический ИИ
- Федеративное обучение
- Квантовые алгоритмы
- ИИ для устройств на краю сети
- Самообучающиеся системы
| Направление | Преимущества | Текущий прогресс | Перспективы |
|---|---|---|---|
| Нейросимволический ИИ | Высокая степень интерпретируемости | 40% готовности | Массовое внедрение к 2027 году |
| Федеративное обучение | Защита конфиденциальности данных | 60% готовности | Широкое применение к 2026 году |
| Квантовые алгоритмы | Ультрашвидкие вычисления | 20% готовности | Практическое использование к 2030 году |
Квантовые алгоритмы представляют собой прорывное направление, способное кардинально изменить методы обработки данных. Несмотря на то, что эта технология все еще находится на начальных этапах своего развития, первые успешные эксперименты уже демонстрируют возможность многократного ускорения вычислительных процессов. Артём Викторович Озеров отмечает: «Мы видим значительный интерес со стороны научного сообщества и фармацевтической отрасли к квантовым алгоритмам для моделирования сложных химических процессов.»
Практические рекомендации
- Исследовать новые методы объяснения работы искусственного интеллекта
- Вкладывать средства в технологии обеспечения безопасности данных
- Отслеживать прогресс в области квантовых технологий
- Изучать возможности гибридных архитектур
- Уделять внимание вычислениям на границе сети
Заключение и дальнейшие шаги
В заключение, можно с уверенностью утверждать, что алгоритмы искусственного интеллекта становятся важной составляющей современных технологических решений, кардинально изменяя методы решения задач в различных сферах. Мы проанализировали основные моменты их функционирования, развитие, практическое использование и будущие перспективы. Необходимо осознавать, что успешная реализация проектов в области ИИ требует комплексного подхода, который учитывает как технические, так и бизнес-аспекты. Эксперты советуют
Этика и ответственность в разработке алгоритмов искусственного интеллекта
Разработка алгоритмов искусственного интеллекта (ИИ) несет в себе не только технические, но и этические вызовы. Этика в контексте ИИ охватывает широкий спектр вопросов, связанных с тем, как технологии влияют на общество, какие последствия могут возникнуть в результате их использования и как обеспечить справедливость и безопасность в их применении.
-
Читайте также:

Одним из ключевых аспектов этики в разработке ИИ является проблема предвзятости алгоритмов. Алгоритмы могут унаследовать предвзятости, существующие в данных, на которых они обучаются. Это может привести к дискриминации определенных групп людей, что вызывает серьезные этические и правовые вопросы. Например, алгоритмы, используемые в системах кредитования или найма, могут неосознанно усиливать социальное неравенство, если они обучены на исторических данных, содержащих предвзятости.
Другим важным аспектом является прозрачность алгоритмов. Пользователи и заинтересованные стороны должны иметь возможность понимать, как принимаются решения, основанные на ИИ. Это требует от разработчиков создания объясняемых моделей, которые могут быть интерпретированы и проверены. Прозрачность помогает укрепить доверие к технологиям и позволяет пользователям осознанно взаимодействовать с ними.
Кроме того, необходимо учитывать вопросы конфиденциальности и защиты данных. Алгоритмы ИИ часто требуют больших объемов личной информации для обучения и функционирования. Это создает риски утечек данных и неправомерного использования личной информации. Этические принципы требуют от разработчиков соблюдения норм защиты данных и обеспечения конфиденциальности пользователей.
Ответственность за последствия использования ИИ также является важным аспектом. Разработчики и компании, внедряющие ИИ, должны осознавать, что их технологии могут иметь далеко идущие последствия для общества. Это включает в себя как положительные, так и отрицательные эффекты, такие как влияние на рынок труда, безопасность и личные права. Поэтому важно, чтобы разработчики учитывали эти аспекты на всех этапах разработки и внедрения технологий.
В заключение, этика и ответственность в разработке алгоритмов ИИ требуют комплексного подхода, который включает в себя не только технические, но и социальные, правовые и философские аспекты. Создание этичных и ответственных технологий ИИ — это задача, требующая сотрудничества между разработчиками, исследователями, законодателями и обществом в целом.
Вопросы этики и социального воздействия
С развитием технологий и внедрением искусственного интеллекта (AI) в различные сферы жизни, вопросы этики и социального воздействия становятся все более актуальными. Искусственный интеллект, обладая способностью обрабатывать и анализировать большие объемы данных, может оказывать значительное влияние на общество, экономику и личную жизнь людей. Однако с этим приходят и серьезные этические дилеммы.
Одним из основных вопросов является проблема предвзятости алгоритмов. AI-системы обучаются на данных, которые могут содержать предвзятости, отражающие социальные, расовые или гендерные стереотипы. Например, если алгоритм для найма сотрудников обучается на исторических данных, где преобладают мужчины, он может не учитывать квалифицированных женщин, что приводит к дискриминации. Это поднимает вопросы о том, как обеспечить справедливость и равенство в использовании AI.
Другой важный аспект — это конфиденциальность данных. AI-системы требуют огромного количества данных для обучения и функционирования, что может привести к сбору и анализу личной информации пользователей. Это вызывает опасения по поводу нарушения приватности и возможности злоупотребления данными. Важно разработать четкие правила и нормы, регулирующие использование личной информации, чтобы защитить права граждан.
Также стоит отметить влияние AI на рынок труда. Автоматизация процессов может привести к сокращению рабочих мест в некоторых отраслях, что вызывает страхи о будущем занятости. В то же время, AI может создать новые рабочие места и повысить производительность. Общество должно подготовиться к этим изменениям, обеспечивая переобучение и адаптацию работников к новым условиям.
Не менее важным является вопрос ответственности за действия AI. Если алгоритм принимает решение, которое приводит к негативным последствиям, кто будет нести ответственность? Это может быть разработчик, компания или сам алгоритм? Необходимы четкие юридические рамки, чтобы определить ответственность и гарантировать защиту прав граждан.
В заключение, этические вопросы и социальное воздействие искусственного интеллекта требуют внимательного изучения и обсуждения. Общество должно активно участвовать в формировании норм и стандартов, которые будут регулировать использование AI, чтобы обеспечить его безопасное и этичное применение в будущем.
Вопрос-ответ
Что такое AI простыми словами?
Искусственный интеллект (ИИ) — это раздел компьютерных наук о создании интеллектуальных систем, которые способны имитировать когнитивные функции человека. Например, обучение, рассуждение, восприятие, понимание языка и принятие решений.
Что такое Al?
✅ Al (artificial intelligence – искусственный интеллект) — ассистент, виртуальный помощник, который помогает сделать занятия проще и интереснее. Это чат-бот с искусственным интеллектом, который обрабатывает запросы пользователей и генерирует ответный текст.
AI алгоритмы это?
По своей сути ИИ — это просто набор инструкций-алгоритмов, который помогает машинам принимать решения. Некоторые из них просты, например, фильтрация спама в электронной почте. Другие — более сложные, например, прогнозирование рисков заболеваний на основе медицинских карт.
Что такое al в нейросети?
Иску́сственный интелле́кт или ИИ, Искусственный разум (англ. Artificial intelligence, AI) в самом широком смысле — это комплекс инструментов, позволяющих решать задачи уровня человеческого интеллекта (такие как восприятие, обучение (learning), рассуждение, решение проблем и принятие решений) и реализованных машинами.
Советы
СОВЕТ №1
Изучайте основы машинного обучения и нейронных сетей, чтобы лучше понять, как работает алгоритм AI. Это поможет вам осознать, какие данные необходимы для обучения и как алгоритмы принимают решения.
СОВЕТ №2
Следите за последними новостями и исследованиями в области искусственного интеллекта. Технологии развиваются очень быстро, и новые подходы могут значительно изменить ваше понимание алгоритмов AI.
СОВЕТ №3
Практикуйтесь в использовании доступных инструментов и библиотек для разработки AI-приложений, таких как TensorFlow или PyTorch. Это даст вам практический опыт и поможет закрепить теоретические знания.
СОВЕТ №4
Общайтесь с профессионалами в области AI и участвуйте в сообществах, чтобы обмениваться опытом и получать советы. Это может быть полезным для решения возникающих вопросов и расширения ваших знаний.
Разработка алгоритмов искусственного интеллекта (ИИ) несет в себе не только технические, но и этические вызовы. Этика в контексте ИИ охватывает широкий спектр вопросов, связанных с тем, как технологии влияют на общество, какие последствия могут возникнуть в результате их использования и как обеспечить справедливость и безопасность в их применении.
Одним из ключевых аспектов этики в разработке ИИ является проблема предвзятости алгоритмов. Алгоритмы могут унаследовать предвзятости, существующие в данных, на которых они обучаются. Это может привести к дискриминации определенных групп людей, что вызывает серьезные этические и правовые вопросы. Например, алгоритмы, используемые в системах кредитования или найма, могут неосознанно усиливать социальное неравенство, если они обучены на исторических данных, содержащих предвзятости.
Другим важным аспектом является прозрачность алгоритмов. Пользователи и заинтересованные стороны должны иметь возможность понимать, как принимаются решения, основанные на ИИ. Это требует от разработчиков создания объясняемых моделей, которые могут быть интерпретированы и проверены. Прозрачность помогает укрепить доверие к технологиям и позволяет пользователям осознанно взаимодействовать с ними.
Кроме того, необходимо учитывать вопросы конфиденциальности и защиты данных. Алгоритмы ИИ часто требуют больших объемов личной информации для обучения и функционирования. Это создает риски утечек данных и неправомерного использования личной информации. Этические принципы требуют от разработчиков соблюдения норм защиты данных и обеспечения конфиденциальности пользователей.
Ответственность за последствия использования ИИ также является важным аспектом. Разработчики и компании, внедряющие ИИ, должны осознавать, что их технологии могут иметь далеко идущие последствия для общества. Это включает в себя как положительные, так и отрицательные эффекты, такие как влияние на рынок труда, безопасность и личные права. Поэтому важно, чтобы разработчики учитывали эти аспекты на всех этапах разработки и внедрения технологий.
В заключение, этика и ответственность в разработке алгоритмов ИИ требуют комплексного подхода, который включает в себя не только технические, но и социальные, правовые и философские аспекты. Создание этичных и ответственных технологий ИИ — это задача, требующая сотрудничества между разработчиками, исследователями, законодателями и обществом в целом.
С развитием технологий и внедрением искусственного интеллекта (AI) в различные сферы жизни, вопросы этики и социального воздействия становятся все более актуальными. Искусственный интеллект, обладая способностью обрабатывать и анализировать большие объемы данных, может оказывать значительное влияние на общество, экономику и личную жизнь людей. Однако с этим приходят и серьезные этические дилеммы.
Одним из основных вопросов является проблема предвзятости алгоритмов. AI-системы обучаются на данных, которые могут содержать предвзятости, отражающие социальные, расовые или гендерные стереотипы. Например, если алгоритм для найма сотрудников обучается на исторических данных, где преобладают мужчины, он может не учитывать квалифицированных женщин, что приводит к дискриминации. Это поднимает вопросы о том, как обеспечить справедливость и равенство в использовании AI.
Другой важный аспект — это конфиденциальность данных. AI-системы требуют огромного количества данных для обучения и функционирования, что может привести к сбору и анализу личной информации пользователей. Это вызывает опасения по поводу нарушения приватности и возможности злоупотребления данными. Важно разработать четкие правила и нормы, регулирующие использование личной информации, чтобы защитить права граждан.
Также стоит отметить влияние AI на рынок труда. Автоматизация процессов может привести к сокращению рабочих мест в некоторых отраслях, что вызывает страхи о будущем занятости. В то же время, AI может создать новые рабочие места и повысить производительность. Общество должно подготовиться к этим изменениям, обеспечивая переобучение и адаптацию работников к новым условиям.
Не менее важным является вопрос ответственности за действия AI. Если алгоритм принимает решение, которое приводит к негативным последствиям, кто будет нести ответственность? Это может быть разработчик, компания или сам алгоритм? Необходимы четкие юридические рамки, чтобы определить ответственность и гарантировать защиту прав граждан.
В заключение, этические вопросы и социальное воздействие искусственного интеллекта требуют внимательного изучения и обсуждения. Общество должно активно участвовать в формировании норм и стандартов, которые будут регулировать использование AI, чтобы обеспечить его безопасное и этичное применение в будущем.