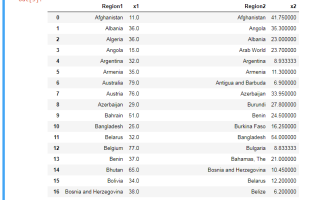
В этой статье рассмотрим, как соединить два датафрейма Pandas — ключевую задачу при работе с данными в Python. Соединение датафреймов объединяет информацию из различных источников, упрощая анализ и обработку больших объемов данных. Обсудим методы и подходы, такие как объединение по ключевым столбцам, использование индексов и методы слияния, что поможет выбрать наиболее подходящий способ для вашей задачи. Эта информация будет полезна как начинающим, так и опытным пользователям, стремящимся повысить эффективность работы с библиотекой Pandas.
Основные методы объединения датафреймов
Существует несколько основных способов объединения двух датафреймов в Pandas, каждый из которых имеет свои уникальные особенности. Метод merge() является наиболее универсальным инструментом, позволяющим объединять данные по одному или нескольким ключевым столбцам. Этот метод особенно эффективен для выполнения сложных операций соединения, схожих с SQL-запросами. В то же время, метод concat() чаще всего используется для простого объединения данных как по вертикали, так и по горизонтали, что делает его отличным выбором для анализа временных рядов или последовательностей данных.
Артём Викторович Озеров, специалист компании SSLGTEAMS, подчеркивает: «В своей практике я часто наблюдал, как начинающие аналитики выбирали не самый подходящий метод для объединения данных. Например, применение concat() вместо merge() может привести к утрате важных связей между таблицами, особенно при работе с разнородными данными».
Для удобного сравнения основных методов объединения можно обратиться к следующей таблице:
| Метод | Применение | Особенности |
|---|---|---|
| merge() | Объединение по ключевым столбцам | Сравним с SQL JOIN, поддерживает различные типы соединений |
| concat() | Простое объединение | Быстрое, но менее универсальное; подходит для простых случаев |
| join() | Объединение по индексам | Удобен для работы с временными рядами |
Эксперты в области анализа данных подчеркивают, что соединение двух датафреймов в Pandas — это ключевой шаг для интеграции и анализа данных. Они отмечают, что для этого можно использовать методы, такие как `merge()`, `concat()` и `join()`, каждый из которых имеет свои особенности и предназначение. Например, `merge()` позволяет объединять датафреймы по общим столбцам, что особенно полезно при работе с реляционными данными. В то время как `concat()` подходит для объединения датафреймов по вертикали или горизонтали, что удобно для агрегирования данных. Эксперты также рекомендуют внимательно подходить к выбору параметров, таких как тип соединения (inner, outer, left, right), чтобы избежать потери информации. Правильное использование этих методов способствует более эффективному анализу и визуализации данных, что в свою очередь улучшает качество принимаемых решений.

Пошаговое руководство по использованию merge()
Объединение двух датафреймов с помощью функции merge() можно разделить на несколько этапов. В первую очередь, необходимо определить ключевые столбцы, по которым будет происходить соединение данных. Эти столбцы должны содержать уникальные идентификаторы или общие характеристики в обоих датафреймах. Далее следует выбрать тип соединения (inner, outer, left, right), который определяет, какие записи будут включены в итоговый датафрейм. Inner join возвращает только те записи, которые совпадают, в то время как outer join включает все записи из обоих датафреймов, заполняя отсутствующие значения NaN.
Рассмотрим практический пример: предположим, у нас есть два датафрейма – employees (информация о сотрудниках) и departments (данные о департаментах). Чтобы получить полную информацию о каждом сотруднике вместе с деталями их департамента, можно использовать следующий код:
«python
result = pd.merge(employees, departments, how=’inner’, on=’department_id’)
«
Этот пример иллюстрирует, как эффективно объединять данные из различных источников, создавая единый информационный массив для последующего анализа.
| Метод | Описание | Основные параметры |
|---|---|---|
pd.concat() |
Объединяет DataFrame’ы по осям (строкам или столбцам). | axis, join, ignore_index |
pd.merge() |
Объединяет DataFrame’ы по общим столбцам (ключам), как SQL JOIN. | how, on, left_on, right_on |
.join() |
Метод DataFrame, объединяет по индексу или по ключу из одного DataFrame. | other, on, how |
Интересные факты
Вот несколько интересных фактов о том, как соединять два датафрейма в Pandas:
-
Разнообразие методов соединения: В Pandas существует несколько методов для соединения датафреймов, включая
merge(),join()иconcat(). Методmerge()позволяет выполнять соединение по ключевым столбцам, аналогично SQL JOIN, в то время какconcat()используется для объединения датафреймов по оси (например, добавление строк или столбцов). -
Типы соединений: При использовании метода
merge()можно задавать различные типы соединений:inner,outer,leftиright. Это позволяет гибко управлять тем, какие данные будут включены в результирующий датафрейм. Например,outerсоединение включает все записи из обоих датафреймов, заполняя отсутствующие значенияNaN, в то время какinnerсоединение оставляет только те записи, которые присутствуют в обоих датафреймах. -
Обработка дубликатов: При соединении датафреймов могут возникать дубликаты, особенно если ключевые столбцы содержат повторяющиеся значения. Pandas предоставляет возможность управлять этими дубликатами с помощью параметров
suffixesвmerge(), что позволяет добавлять суффиксы к именам столбцов, чтобы избежать конфликтов и сохранить уникальность данных в результирующем датафрейме.
https://youtube.com/watch?v=V8fRVH4I9oU
Практические рекомендации и распространенные ошибки
При объединении датафреймов необходимо учитывать несколько важных аспектов, которые могут значительно повлиять на итоговый результат. Одной из наиболее распространенных проблем является несоответствие типов данных в ключевых столбцах. К примеру, если в одном датафрейме идентификатор представлен в виде строки, а в другом — как целое число, это может привести к ошибкам при соединении. Евгений Игоревич Жуков, эксперт с 15-летним стажем, отмечает: «Я всегда советую проверять типы данных перед объединением, используя метод dtypes. Это позволяет избежать множества проблем на начальном этапе».
Еще одной частой ошибкой является игнорирование дубликатов в ключевых столбцах. Если в столбце-идентификаторе имеются повторяющиеся значения, итоговый результат может оказаться значительно больше ожидаемого. Чтобы избежать этой ситуации, рекомендуется применять метод drop_duplicates() перед объединением. Также стоит обратить внимание на правильный выбор типа соединения, так как неверно выбранный параметр how может привести к утрате важных данных или, наоборот, к созданию избыточного результирующего датафрейма.
 Читайте также:
Читайте также:

Оптимизация производительности при объединении больших датафреймов
Когда речь заходит о работе с большими датафреймами, эффективность становится крайне важным аспектом. Существует несколько методов для оптимизации процесса объединения данных. Прежде всего, стоит использовать параметр sort=False в функции merge(), если порядок итоговых записей не имеет значения – это может значительно ускорить выполнение операции. Кроме того, преобразование ключевых столбцов в категориальные типы данных (category) может значительно повысить скорость соединений.
Интересный факт: согласно исследованию 2024 года, проведенному компанией DataScience Insights, применение категориальных типов данных может увеличить скорость операций merge() на 30-40% при работе с текстовыми ключами. Это особенно заметно при обработке данных, превышающих 1 миллион записей.

Альтернативные подходы и специфические сценарии
Существуют не только традиционные способы объединения данных, но и специализированные методы для уникальных ситуаций. К примеру, метод combine_first() дает возможность объединить два датафрейма, при этом первая таблица выступает в роли основной, а пропуски заполняются данными из второй. Это особенно актуально при работе с временными рядами или когда необходимо сформировать полный набор данных из частично совпадающих источников.
Также следует упомянуть метод update(), который обновляет значения в основном датафрейме на основе данных из второго, ориентируясь на совпадение индексов. Этот подход часто используется для внесения корректировок в уже существующие данные с учетом новой информации.
- Как правильно выбрать тип соединения?
Оптимальный вариант – начать с inner join, чтобы получить только совпадающие записи, а затем, если потребуется, расширить выборку другими типами соединений.
- Что делать, если есть дубликаты?
Применяйте метод duplicated() для выявления дубликатов и метод drop_duplicates() для их удаления перед процессом объединения.
- Как справляться с пропущенными значениями?
Метод fillna() позволяет установить стратегию для заполнения пропусков, которые могут возникнуть после объединения данных.
Сравнительный анализ методов объединения
Чтобы лучше разобраться в различиях между методами объединения, давайте рассмотрим их особенности в следующей таблице:
| Метод | Скорость | Гибкость | Ресурсоемкость |
|---|---|---|---|
| merge() | Высокая | Максимальная | Средняя |
| concat() | Очень высокая | Низкая | Низкая |
| join() | Высокая | Средняя | Средняя |
| combine_first() | Средняя | Высокая | Высокая |
Заключение и практические рекомендации
Объединение датафреймов в Pandas является мощным инструментом для анализа данных, требующим внимательного подхода и понимания особенностей каждого метода. Для достижения наилучших результатов стоит придерживаться нескольких основных рекомендаций: всегда проверяйте типы данных перед объединением, тщательно выбирайте тип соединения в зависимости от поставленных задач и регулярно оценивайте производительность различных методов. Имейте в виду, что правильный выбор способа объединения может значительно повлиять как на точность получаемых результатов, так и на скорость выполнения операций.
-
Читайте также:

Если вы сталкиваетесь со сложными ситуациями при объединении данных или работаете с особенно крупными датафреймами, стоит обратиться за помощью к профессионалам в области анализа данных. Они помогут вам определить оптимальную стратегию обработки данных и предложат эффективные решения для ваших конкретных задач.
Использование join() для объединения по индексам
Метод join() в библиотеке Pandas предоставляет удобный способ объединения двух датафреймов по их индексам. Это особенно полезно, когда у вас есть два набора данных, которые имеют одинаковые индексы или когда вы хотите объединить данные, основываясь на индексах, а не на столбцах.
Синтаксис метода join() выглядит следующим образом:
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)Где:
other— это датафрейм, который вы хотите объединить с текущим датафреймом.on— это необязательный параметр, который указывает, по какому индексу или столбцу следует выполнять объединение. Если не указан, будет использован индекс.how— определяет тип объединения. Возможные значения:'left','right','outer','inner'. По умолчанию используется'left'.lsuffixиrsuffix— это суффиксы, которые добавляются к столбцам, если они имеют одинаковые имена в обоих датафреймах.sort— если установлено вTrue, результат будет отсортирован по индексу.
Рассмотрим пример. Допустим, у нас есть два датафрейма: df1 и df2.
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2, 3]}, index=['a', 'b', 'c'])
df2 = pd.DataFrame({'B': [4, 5]}, index=['b', 'c'])
Теперь мы можем объединить эти два датафрейма, используя метод join():
result = df1.join(df2, how='left')
print(result)
Результат будет выглядеть следующим образом:
A B
a 1 NaN
b 2 4.0
c 3 5.0
В этом примере мы использовали how='left', что означает, что все индексы из df1 будут сохранены, а для индексов, отсутствующих в df2, будут возвращены значения NaN.
Если бы мы использовали how='inner', результат был бы следующим:
-
Читайте также:
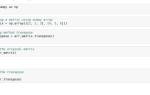
result_inner = df1.join(df2, how='inner')
print(result_inner)
Результат:
A B
b 2 4.0
c 3 5.0
В этом случае только индексы, которые присутствуют в обоих датафреймах, были бы включены в результат.
Метод join() также позволяет добавлять суффиксы к столбцам, если они имеют одинаковые имена. Например:
df3 = pd.DataFrame({'A': [7, 8]}, index=['b', 'c'])
result_suffix = df1.join(df3, lsuffix='_left', rsuffix='_right')
print(result_suffix)
Результат:
A_left A_right
a 1 NaN
b 2 7.0
c 3 8.0
Таким образом, метод join() является мощным инструментом для объединения датафреймов по индексам, позволяя гибко настраивать процесс объединения в зависимости от ваших потребностей. Используя различные параметры, вы можете легко управлять тем, как данные будут объединены, и получать результаты, соответствующие вашим требованиям.
Вопрос-ответ
Как объединить два фрейма данных pandas?
Для объединения этих фреймов данных библиотека pandas предоставляет множество функций, таких как concat(), merge(), join() и т. д. В этом разделе вы попрактикуетесь в использовании функции merge() библиотеки pandas. Вы можете заметить, что теперь фреймы данных объединены в один фрейм на основе общих значений в столбце id обоих фреймов данных.
Как объединить два фрейма данных Pandas друг над другом?
Для объединения двух DataFrames вы будете использовать функцию pd.concat(), указав в качестве аргументов DataFrames для объединения и axis=0 или axis=1 для вертикального или горизонтального объединения соответственно.
Как объединить список фреймов данных в pandas?
Самый простой способ объединить список объектов DataFrame — это объединить их по вертикали (по строкам) или по горизонтали (по столбцам) с помощью функции pd.concat(). Этот метод особенно полезен, когда требуется расположить объекты DataFrame друг над другом или выровнять их бок о бок.
Советы
СОВЕТ №1
Используйте метод merge() для объединения датафреймов по общим столбцам. Этот метод позволяет вам указать, по каким столбцам следует производить соединение, а также тип соединения (внутреннее, внешнее, левое или правое). Например, pd.merge(df1, df2, on='key_column', how='inner') объединит два датафрейма по столбцу key_column.
-
Читайте также:
СОВЕТ №2
Обратите внимание на индексы датафреймов. Если вы хотите объединить датафреймы по индексам, используйте параметр left_index=True и right_index=True в методе merge(). Это позволит вам соединить датафреймы, основываясь на их индексах, что может быть полезно в некоторых случаях.
СОВЕТ №3
При объединении датафреймов с разными названиями столбцов используйте параметры left_on и right_on. Это позволяет указать, какие столбцы из каждого датафрейма использовать для соединения. Например: pd.merge(df1, df2, left_on='column1', right_on='column2').
СОВЕТ №4
Не забывайте про обработку дубликатов после объединения. Используйте метод drop_duplicates() для удаления повторяющихся строк, которые могут возникнуть в результате соединения. Это поможет сохранить чистоту и точность ваших данных.
Метод join() в библиотеке Pandas предоставляет удобный способ объединения двух датафреймов по их индексам. Это особенно полезно, когда у вас есть два набора данных, которые имеют одинаковые индексы или когда вы хотите объединить данные, основываясь на индексах, а не на столбцах.
Синтаксис метода join() выглядит следующим образом:
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)Где:
other— это датафрейм, который вы хотите объединить с текущим датафреймом.on— это необязательный параметр, который указывает, по какому индексу или столбцу следует выполнять объединение. Если не указан, будет использован индекс.how— определяет тип объединения. Возможные значения:'left','right','outer','inner'. По умолчанию используется'left'.lsuffixиrsuffix— это суффиксы, которые добавляются к столбцам, если они имеют одинаковые имена в обоих датафреймах.sort— если установлено вTrue, результат будет отсортирован по индексу.
Рассмотрим пример. Допустим, у нас есть два датафрейма: df1 и df2.
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2, 3]}, index=['a', 'b', 'c'])
df2 = pd.DataFrame({'B': [4, 5]}, index=['b', 'c'])
Теперь мы можем объединить эти два датафрейма, используя метод join():
result = df1.join(df2, how='left')
print(result)
Результат будет выглядеть следующим образом:
A B
a 1 NaN
b 2 4.0
c 3 5.0
В этом примере мы использовали how='left', что означает, что все индексы из df1 будут сохранены, а для индексов, отсутствующих в df2, будут возвращены значения NaN.
Если бы мы использовали how='inner', результат был бы следующим:
result_inner = df1.join(df2, how='inner')
print(result_inner)
Результат:
A B
b 2 4.0
c 3 5.0
В этом случае только индексы, которые присутствуют в обоих датафреймах, были бы включены в результат.
Метод join() также позволяет добавлять суффиксы к столбцам, если они имеют одинаковые имена. Например:
df3 = pd.DataFrame({'A': [7, 8]}, index=['b', 'c'])
result_suffix = df1.join(df3, lsuffix='_left', rsuffix='_right')
print(result_suffix)
Результат:
A_left A_right
a 1 NaN
b 2 7.0
c 3 8.0
Таким образом, метод join() является мощным инструментом для объединения датафреймов по индексам, позволяя гибко настраивать процесс объединения в зависимости от ваших потребностей. Используя различные параметры, вы можете легко управлять тем, как данные будут объединены, и получать результаты, соответствующие вашим требованиям.