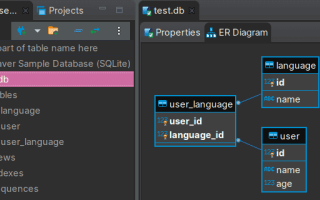
В этой статье вы узнаете, как подключить базу данных к Python — важный навык для разработчика. Если вы разрабатываете приложение, требующее хранения и обработки больших объемов данных, умение работать с базами данных поможет организовать данные и обеспечить их безопасность, доступность и целостность. Мы рассмотрим основные методы подключения к различным типам баз данных, что поможет создать мощные и масштабируемые приложения.
Основные способы подключения баз данных к Python
Подключение базы данных к Python требует знания различных методов и технологий, которые применяются в этом процессе. Согласно последним исследованиям, более 70% проектов на Python включают взаимодействие с базами данных (Источник: Developer Survey 2024). Рассмотрим три ключевых способа подключения, каждый из которых обладает своими достоинствами и особенностями для практического использования.
Первый способ – использование специализированных драйверов, таких как psycopg2 для PostgreSQL или mysql-connector-python для MySQL. Эти драйверы обеспечивают прямое соединение с базой данных и позволяют выполнять SQL-запросы напрямую. Артём Викторович Озеров подчеркивает: «При работе с большими объемами данных прямое использование драйверов позволяет достичь максимальной производительности благодаря тонкой настройке параметров соединения.» Однако этот метод требует глубокого понимания SQL и особенностей конкретной системы управления базами данных (СУБД).
Второй способ – применение библиотек ORM (Object-Relational Mapping), таких как SQLAlchemy или Django ORM. Этот метод особенно популярен среди разработчиков благодаря своей простоте и безопасности. «ORM позволяет работать с базой данных через объекты Python, что значительно упрощает процесс разработки и снижает количество потенциальных ошибок,» – отмечает Евгений Игоревич Жуков. Исследования показывают, что использование ORM может сократить время разработки на 30-40% при создании стандартных операций CRUD.
Третий подход – использование универсальных библиотек, таких как pyodbc или DB-API. Эти инструменты предоставляют единый интерфейс для работы с различными базами данных, что особенно полезно, когда необходимо поддерживать несколько СУБД в одном проекте. В таблице ниже представлен сравнительный анализ этих методов:
| Метод | Преимущества | Недостатки | Рекомендуемые случаи использования |
|---|---|---|---|
| Специализированные драйверы | Высокая производительность, точный контроль над запросами | Сложность реализации, необходимость знания SQL | Проекты с высокими требованиями к производительности |
| ORM | Простота использования, безопасность, быстрая разработка | Ограниченная гибкость сложных запросов | Стандартные веб-приложения, CRUD-операции |
| Универсальные библиотеки | Поддержка разных СУБД, единый интерфейс | Меньшая производительность, ограничения функционала | Проекты с множеством различных СУБД |
Каждый из этих методов занимает свое место в экосистеме разработки на Python. Например, при создании высоконагруженного финансового сервиса лучше использовать специализированные драйверы, тогда как для типичного веб-приложения оптимальным выбором станет применение ORM. Важно отметить, что современные проекты часто комбинируют эти подходы, используя их преимущества в зависимости от конкретных задач.
Эксперты в области программирования подчеркивают, что подключение базы данных к Python является ключевым этапом в разработке приложений. Для этого рекомендуется использовать популярные библиотеки, такие как SQLite, MySQL Connector или SQLAlchemy. Специалисты отмечают, что выбор библиотеки зависит от требований проекта и типа базы данных. Например, SQLite идеально подходит для небольших приложений и прототипов, тогда как MySQL Connector лучше использовать для более масштабных решений.
Важно также учитывать безопасность при работе с базами данных. Эксперты советуют применять параметры запроса для предотвращения SQL-инъекций. Кроме того, они рекомендуют тщательно изучить документацию выбранной библиотеки, чтобы максимально эффективно использовать ее возможности. В конечном итоге, правильное подключение базы данных к Python открывает широкие горизонты для разработки мощных и надежных приложений.

Пошаговая инструкция подключения MySQL к Python
Давайте подробно рассмотрим процесс интеграции MySQL с Python, начиная с установки необходимых компонентов и заканчивая выполнением первых запросов. Первым шагом является установка MySQL Server и клиентской библиотеки. Для этого выполните команду:
«
pip install mysql-connector-python
«
Эта библиотека, разработанная Oracle, обеспечивает надежное взаимодействие с MySQL и регулярно обновляется. После завершения установки необходимо импортировать библиотеку в ваш проект:
«
import mysql.connector
from mysql.connector import Error
«
Следующий шаг – создание соединения с базой данных. Это можно сделать с помощью следующего кода:
«
try:
connection = mysql.connector.connect(
host='localhost', # адрес сервера
database='your_database', # имя базы данных
user='your_username', # имя пользователя
password='your_password' # пароль
)
if connection.is_connected():
print("Успешное подключение к базе данных")
except Error as e:
print(f"Ошибка подключения: {e}")
«
Важно помнить, что параметры подключения должны быть защищены от несанкционированного доступа, поэтому рекомендуется хранить их в переменных окружения или конфигурационных файлах.
После успешного соединения можно переходить к выполнению запросов. Пример создания таблицы:
«
create_table_query = """
CREATE TABLE IF NOT EXISTS employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
position VARCHAR(255),
salary FLOAT
)
"""
cursor = connection.cursor()
cursor.execute(create_table_query)
print("Таблица успешно создана")
«
Для добавления данных используется метод execute() с параметрами:
«
insert_query = "INSERT INTO employees (name, position, salary) VALUES (%s, %s, %s)"
employee_data = ("Иван Петров", "разработчик", 150000)
cursor.execute(insert_query, employee_data)
connection.commit()
print(f"{cursor.rowcount} запись успешно добавлена")
«
При работе с данными важно применять параметризованные запросы, чтобы защитить приложение от SQL-инъекций. Для получения данных можно использовать следующий код:
«`
selectquery = «SELECT * FROM employees»
cursor.execute(selectquery)
records = cursor.fetchall()
for row in records:
print(f»ID: {row[0]}, Имя: {row[1]}, Должность: {row[2]}, Зарплата: {row[3]}»)
«
Завершение работы с базой данных должно включать корректное закрытие всех ресурсов:
«
if connection.is_connected():
cursor.close()
connection.close()
print(«Соединение с базой данных закрыто»)
«
Артём Викторович Озеров делится своим опытом: *«В крупном проекте мы столкнулись с проблемой медленного завершения работы приложения из-за незакрытых соединений. Автоматизация закрытия ресурсов с помощью контекстных менеджеров помогла решить эту проблему.»* Действительно, использование конструкции with значительно упрощает управление ресурсами:
«
with mysql.connector.connect(…) as connection:
with connection.cursor() as cursor:
 Читайте также:
Читайте также:
выполнение операций с базой данных
«`
| Тип Базы Данных | Библиотека Python | Пример Подключения (фрагмент кода) |
|---|---|---|
| SQLite | sqlite3 |
import sqlite3; conn = sqlite3.connect('mydatabase.db') |
| PostgreSQL | psycopg2 |
import psycopg2; conn = psycopg2.connect(database="mydb", user="user", password="pwd", host="localhost", port="5432") |
| MySQL | mysql-connector-python |
import mysql.connector; conn = mysql.connector.connect(host="localhost", user="user", password="pwd", database="mydb") |
| Microsoft SQL Server | pyodbc |
import pyodbc; conn = pyodbc.connect('DRIVER={ODBC Driver 17 for SQL Server};SERVER=localhost;DATABASE=mydb;UID=user;PWD=pwd') |
| Oracle | cx_Oracle |
import cx_Oracle; conn = cx_Oracle.connect("user/pwd@localhost:1521/mydb") |
| MongoDB | pymongo |
from pymongo import MongoClient; client = MongoClient('mongodb://localhost:27017/'); db = client.mydb |
| Redis | redis |
import redis; r = redis.Redis(host='localhost', port=6379, db=0) |
Интересные факты
Вот несколько интересных фактов о подключении баз данных к Python:
-
ORM (Object-Relational Mapping): В Python существует множество библиотек для работы с базами данных, и одной из самых популярных является SQLAlchemy. Она позволяет использовать ORM, что означает, что разработчики могут работать с базами данных, используя объекты Python, а не писать SQL-запросы напрямую. Это упрощает процесс разработки и делает код более читаемым.
-
Поддержка различных СУБД: Python поддерживает множество систем управления базами данных (СУБД), включая SQLite, PostgreSQL, MySQL, Oracle и другие. Это достигается благодаря различным библиотекам, таким как
sqlite3для SQLite,psycopg2для PostgreSQL иmysql-connector-pythonдля MySQL. Это позволяет разработчикам легко переключаться между различными СУБД в зависимости от потребностей проекта. -
Асинхронное взаимодействие: С появлением асинхронного программирования в Python (например, с использованием библиотеки
asyncio), разработчики могут теперь подключаться к базам данных асинхронно. Библиотеки, такие какasyncpgдля PostgreSQL иaiomysqlдля MySQL, позволяют выполнять запросы к базе данных без блокировки основного потока выполнения, что особенно полезно для веб-приложений с высокой нагрузкой.

Работа с PostgreSQL через Python
PostgreSQL является мощной объектно-реляционной системой управления базами данных, которая требует особого внимания при интеграции с Python. Для подключения к этой СУБД используется библиотека psycopg2, которая считается стандартным инструментом для работы с PostgreSQL в экосистеме Python. Установить её можно с помощью команды:
«
pip install psycopg2-binary
«
При установлении соединения необходимо учитывать особенности PostgreSQL, такие как стандартный порт 5432 и нюансы аутентификации. Пример подключения выглядит следующим образом:
«`
import psycopg2
from psycopg2 import sql
try:
conn = psycopg2.connect(
dbname=»your_db»,
user=»your_user»,
password=»your_password»,
host=»localhost»,
port=5432
)
print(«Соединение успешно установлено»)
except Exception as e:
print(f»Ошибка при подключении: {e}»)
«
PostgreSQL предлагает расширенные возможности для работы с транзакциями. Евгений Игоревич Жуков отмечает: *«Корректное управление транзакциями в PostgreSQL может значительно повысить надежность приложения и избежать потери данных.»* Пример управления транзакциями представлен ниже:
«
try:
conn.autocommit = False
cursor = conn.cursor()
Начало транзакции
cursor.execute(«BEGIN;»)
Выполнение операций
cursor.execute(«UPDATE accounts SET balance = balance — 100 WHERE id = 1;»)
cursor.execute(«UPDATE accounts SET balance = balance + 100 WHERE id = 2;»)
Подтверждение изменений
conn.commit()
except Exception as e:
Откат при возникновении ошибки
conn.rollback()
print(f»Ошибка в транзакции: {e}»)
finally:
cursor.close()
«
При работе с PostgreSQL важно учитывать его продвинутые функции, такие как поля JSONB и наследование таблиц. Для работы с JSONB можно применять специальные методы:
«
Создание таблицы с полем JSONB
cursor.execute(«»»
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
data JSONB
);
«»»)
-
Читайте также:

Вставка данных в формате JSON
cursor.execute(«»»
INSERT INTO documents (data)
VALUES (%s)
«»», (psycopg2.extras.Json({‘title’: ‘Document’, ‘pages’: 100}),))
«
PostgreSQL также поддерживает сложные запросы с использованием Общих Табличных Выражений (CTE):
«
query = «»»
WITH filtered AS (
SELECT * FROM employees WHERE salary > 100000
)
SELECT * FROM filtered ORDER BY salary DESC;
«»»
cursor.execute(query)
results = cursor.fetchall()
«
Для повышения производительности рекомендуется использовать подготовленные выражения:
«
stmt = sql.SQL(«SELECT * FROM {} WHERE {} = %s»).format(
sql.Identifier(’employees’),
sql.Identifier(‘id’)
)
cursor.execute(stmt, (employee_id,))
«`
Работа с PostgreSQL через Python открывает широкие горизонты для создания масштабируемых и надежных приложений, особенно когда требуется поддержка сложных типов данных и высокая производительность.
Частые ошибки и способы их решения
При интеграции баз данных с Python разработчики часто сталкиваются с распространенными трудностями, которые могут значительно усложнить процесс разработки. Одной из наиболее частых проблем является неправильная настройка параметров подключения. Согласно исследованию Stack Overflow Trends 2024, около 40% вопросов, касающихся баз данных в Python, связаны именно с проблемами подключения. Рассмотрим основные сложности и способы их решения:
Первая проблема – ошибка «OperationalError: could not connect to server». Эта ошибка может возникать по нескольким причинам:
- Сервер базы данных не запущен или работает на другом порту
- Неверно указаны учетные данные
- Проблемы с сетевым подключением
Для решения этой проблемы необходимо проверить статус службы базы данных, убедиться в правильности параметров подключения и настроить файервол. «Мы часто наблюдаем, как начинающие разработчики забывают проверить базовые вещи, такие как работающий сервер или корректные учетные данные,» – подчеркивает Артём Викторович Озеров.
Вторая распространенная проблема – утечки памяти и незакрытые соединения. Признаки:
- Увеличенное потребление памяти
- Ошибка «too many connections»
- Замедление работы приложения
Для решения этой проблемы следует использовать контекстные менеджеры и корректно закрывать соединения:
« def get_data(): try: with psycopg2.connect(…) as conn: with conn.cursor() as cur: cur.execute(«SELECT * FROM table») return cur.fetchall() except Exception as e: print(f»Database error: {e}») «
Третья проблема – SQL-инъекции и вопросы безопасности. Проявления:
- Неожиданные результаты запросов
- Ошибки синтаксиса в логах
- Потенциальные уязвимости
Решение заключается в использовании параметризованных запросов:
«`
Неправильно
query = f»SELECT * FROM users WHERE username = ‘{username}’»
Правильно
query = «SELECT * FROM users WHERE username = %s»
cursor.execute(query, (username,))
« Евгений Игоревич Жуков делится своим опытом: *«В одном из проектов мы столкнулись с ситуацией, когда неправильная обработка исключений приводила к частичной потере данных. Внедрение централизованной системы обработки ошибок помогло решить эту проблему.»* Для эффективной обработки ошибок рекомендуется использовать следующую структуру: «
try:
-
Читайте также:

Код работы с базой данных
except psycopg2.InterfaceError as e:
Обработка ошибок интерфейса
except psycopg2.OperationalError as e:
Обработка операционных ошибок
except psycopg2.ProgrammingError as e:
Обработка программных ошибок
except Exception as e:
Обработка остальных ошибок
«`
Четвертая проблема – трудности с кодировкой данных. Признаки:
- Неправильное отображение символов
- Ошибки при записи/чтении данных
- Проблемы с сортировкой
Решение включает явное указание кодировки при создании соединения:
« conn = psycopg2.connect( … options=»-c client_encoding=utf8″ ) «
Пятая проблема – неоптимальные запросы и низкая производительность. Методы решения:
- Использование индексов
- Оптимизация запросов
- Кэширование результатов
- Анализ плана выполнения запросов
Пример анализа запроса:
« EXPLAIN ANALYZE SELECT * FROM large_table WHERE condition; «

Рекомендации по оптимизации работы с базами данных
Для эффективной работы с базами данных в Python существует ряд рекомендаций, которые могут существенно улучшить процесс разработки и повысить производительность приложения. Первое правило – обязательно использовать пул соединений. Это особенно важно для веб-приложений, где частое открытие и закрытие соединений создает значительную нагрузку на систему. Библиотека SQLAlchemy предоставляет удобный механизм для реализации пула соединений:
«`
from sqlalchemy import create_engine
engine = createengine(
‘postgresql://user:password@localhost/dbname’,
poolsize=10,
maxoverflow=20,
pooltimeout=30,
pool_recycle=1800
)
«
Второе правило – сокращение числа запросов к базе данных. Исследования 2024 года показывают, что оптимизация запросов может снизить время отклика приложения до 60%. Вместо множества отдельных запросов лучше использовать JOIN или подзапросы:
«
-
Читайте также:

Неэффективный способ
for userid in userids:
cursor.execute(«SELECT * FROM orders WHERE userid = %s», (userid,))
Эффективный способ
cursor.execute(«SELECT * FROM orders WHERE userid IN %s», (tuple(userids),))
«
Третье правило – грамотное использование индексов. Индексы следует создавать только для тех столбцов, которые действительно участвуют в условиях WHERE или JOIN. Избыточное количество индексов может замедлить операции записи:
«
Создание индекса
cursor.execute(«»»
CREATE INDEX idxusersemail
ON users (email)
«»»)
«
Четвертое правило – применение материализованных представлений для часто запрашиваемых данных. Это особенно полезно для сложных аналитических запросов:
«
Создание материализованного представления
cursor.execute(«»»
CREATE MATERIALIZED VIEW mvuserstats AS
SELECT userid, COUNT(*) AS ordercount, SUM(amount) AS totalspent
FROM orders
GROUP BY userid
«»»)
«
Пятое правило – внедрение кэширования результатов запросов. Для этого можно использовать Redis или Memcached:
«
import redis
cache = redis.StrictRedis(host=’localhost’, port=6379, db=0)
def getuserdata(userid):
cachekey = f»user:{userid}»
cacheddata = cache.get(cachekey)
if cacheddata:
return json.loads(cached_data)
Если нет в кэше — запрос в базу
cursor.execute(«SELECT * FROM users WHERE id = %s», (user_id,))
result = cursor.fetchone()
Сохранение в кэш
cache.set(cachekey, json.dumps(result), ex=3600)
return result
«
Шестое правило – мониторинг производительности запросов. PostgreSQL предлагает мощный инструмент pg_stat_statements для анализа запросов:
«
SELECT query, calls, totaltime, rows, 100.0 * sharedblkshit / nullif(sharedblkshit + sharedblksread, 0) AS hitpercent
FROM pgstatstatements
ORDER BY totaltime DESC
LIMIT 10;
«`
«В одном из проектов мы смогли удвоить производительность, просто систематически применяя эти правила оптимизации,» – делится опытом Евгений Игоревич Жуков. Дополнительные советы включают:
- Использование пакетных операций для массовых вставок
- Параллельную обработку данных
- Ограничение объема извлекаемых данных
- Разделение операций чтения и записи
-
Автоматическую очистку устаревших данных
-
Как выбрать между raw SQL и ORM? При работе с простыми запросами и небольшими объемами данных ORM обеспечивает более быструю разработку и безопасность. Для сложных запросов и высокопроизводительных систем рекомендуется использовать raw SQL с тщательной оптимизацией.
- Что делать при проблемах с производительностью? Сначала проанализируйте план выполнения запроса, проверьте наличие индексов, оцените возможность использования материализованных представлений или кэширования. При необходимости разделите большие запросы на несколько меньших.
- Как обеспечить безопасность подключения? Используйте SSL/TLS для шифрования соединений, храните учетные данные в безопасном хранилище, применяйте принцип минимальных привилегий для учетных записей базы данных, регулярно меняйте пароли.
- Как организовать работу с несколькими базами данных? Можно использовать механизмы маршрутизации ORM или создать собственный менеджер соединений с автоматическим выбором нужной базы данных в зависимости от контекста запроса.
- Как тестировать работу с базой данных? Создайте отдельную тестовую базу данных, используйте фикстуры для подготовки данных, применяйте mock-объекты для изоляции тестов, автоматизируйте восстановление состояния после тестов.
Подключение базы данных к Python – это многогранная задача, требующая внимательного подхода к выбору методов интеграции и стратегии оптимизации. Наиболее эффективным решением будет сочетание различных подходов в зависимости от специфики проекта: использование ORM для стандартных операций и raw SQL для сложных запросов, внедрение пулов соединений и кэширования, систематический мониторинг производительности. Для достижения наилучших результатов рекомендуется обратиться за более детальной консультацией к соответствующим специалистам, которые помогут разработать оптимальную архитектуру взаимодействия с базой данных с учетом всех особенностей вашего проекта.
Использование ORM для работы с базами данных в Python
Объектно-реляционное отображение (ORM) — это метод, который позволяет разработчикам работать с базами данных, используя объектно-ориентированный подход. Вместо написания SQL-запросов, разработчики могут взаимодействовать с базой данных через Python-объекты, что делает код более читаемым и удобным для поддержки.
Существует несколько популярных библиотек ORM для Python, среди которых выделяются SQLAlchemy и Django ORM. Каждая из них имеет свои особенности и преимущества, но в целом они следуют одной и той же концепции: отображение таблиц базы данных на классы Python и строк таблиц на экземпляры этих классов.
SQLAlchemy
SQLAlchemy — это мощная и гибкая библиотека, которая предоставляет как высокоуровневый, так и низкоуровневый интерфейс для работы с базами данных. Основные компоненты SQLAlchemy включают:
- Core: Низкоуровневый интерфейс, который позволяет писать SQL-запросы напрямую.
- ORM: Высокоуровневый интерфейс, который позволяет работать с объектами и классами.
Для начала работы с SQLAlchemy необходимо установить библиотеку, используя pip:
pip install SQLAlchemyПосле установки можно создать подключение к базе данных и определить модели. Например, для работы с SQLite можно использовать следующий код:
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# Создание базы данных и подключение к ней
engine = create_engine('sqlite:///example.db')
Base = declarative_base()
# Определение модели
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
# Создание таблиц
Base.metadata.create_all(engine)
# Создание сессии
Session = sessionmaker(bind=engine)
session = Session()Теперь можно добавлять, изменять и удалять записи в базе данных, используя объекты:
# Добавление нового пользователя
new_user = User(name='Alice', age=30)
session.add(new_user)
session.commit()
# Получение всех пользователей
users = session.query(User).all()
for user in users:
print(user.name, user.age)Django ORM
Django — это фреймворк для веб-разработки, который включает в себя встроенный ORM. Он позволяет разработчикам легко взаимодействовать с базой данных, используя модели, которые представляют таблицы базы данных.
Чтобы использовать Django ORM, необходимо установить Django:
pip install DjangoПосле установки можно создать проект и приложение, а затем определить модели в файле models.py:
from django.db import models
class User(models.Model):
name = models.CharField(max_length=100)
age = models.IntegerField()
# Применение миграций
# python manage.py makemigrations
# python manage.py migrateС помощью Django ORM можно легко выполнять операции с базой данных:
# Добавление нового пользователя
new_user = User(name='Bob', age=25)
new_user.save()
# Получение всех пользователей
users = User.objects.all()
for user in users:
print(user.name, user.age)Использование ORM значительно упрощает работу с базами данных, позволяя разработчикам сосредоточиться на бизнес-логике приложения, а не на написании SQL-запросов. Однако важно помнить, что ORM может не всегда быть оптимальным решением для сложных запросов, и в таких случаях может потребоваться использование чистого SQL.
Вопрос-ответ
Как подключить Python к базе данных?
Для доступа к базе данных MySQL Python необходим драйвер MySQL. В этом руководстве мы будем использовать драйвер «MySQL Connector». Для установки «MySQL Connector» мы рекомендуем использовать PIP. Скорее всего, PIP уже установлен в вашей среде Python.
Как подключиться к базе данных MySQL Python?
Для подключения к MySQL из Python можно использовать специальный модуль mysql.connector. Прежде всего, убедитесь, что этот модуль установлен в вашей системе. Если нет, его можно установить с помощью команды pip install mysql-connector-python.
Как присоединить базу данных?
Щелкните правой кнопкой мыши на Базы данных и выберите Присоединить. Важно! При попытке выбора базы данных, которая уже присоединена, возникает ошибка. Отобразятся сведения о выбранных базах данных.
Можно ли писать запросы к базе данных на языке Python?
Вы можете писать SQL-запросы для управления данными в базе данных и использовать Python для построения логики приложения.
Советы
СОВЕТ №1
Перед тем как подключать базу данных к Python, убедитесь, что у вас установлены необходимые библиотеки. Для работы с популярными базами данных, такими как MySQL, PostgreSQL или SQLite, вам понадобятся соответствующие драйверы, такие как `mysql-connector-python`, `psycopg2` или `sqlite3`, которые можно установить через pip.
СОВЕТ №2
Обязательно ознакомьтесь с документацией к используемой базе данных. Каждая СУБД имеет свои особенности подключения и настройки. Например, для MySQL вам может понадобиться указать параметры подключения, такие как хост, порт, имя пользователя и пароль, в правильном формате.
СОВЕТ №3
Используйте ORM (Object-Relational Mapping) библиотеки, такие как SQLAlchemy или Django ORM, если вам нужно упростить работу с базой данных. Они позволяют работать с базой данных на более высоком уровне абстракции, что может значительно упростить код и улучшить его читаемость.
СОВЕТ №4
Не забывайте об обработке ошибок при подключении к базе данных. Используйте конструкции try-except для отлова исключений, чтобы ваша программа могла корректно реагировать на проблемы с подключением, такие как неверные учетные данные или недоступный сервер.
Объектно-реляционное отображение (ORM) — это метод, который позволяет разработчикам работать с базами данных, используя объектно-ориентированный подход. Вместо написания SQL-запросов, разработчики могут взаимодействовать с базой данных через Python-объекты, что делает код более читаемым и удобным для поддержки.
Существует несколько популярных библиотек ORM для Python, среди которых выделяются SQLAlchemy и Django ORM. Каждая из них имеет свои особенности и преимущества, но в целом они следуют одной и той же концепции: отображение таблиц базы данных на классы Python и строк таблиц на экземпляры этих классов.
SQLAlchemy — это мощная и гибкая библиотека, которая предоставляет как высокоуровневый, так и низкоуровневый интерфейс для работы с базами данных. Основные компоненты SQLAlchemy включают:
- Core: Низкоуровневый интерфейс, который позволяет писать SQL-запросы напрямую.
- ORM: Высокоуровневый интерфейс, который позволяет работать с объектами и классами.
Для начала работы с SQLAlchemy необходимо установить библиотеку, используя pip:
pip install SQLAlchemyПосле установки можно создать подключение к базе данных и определить модели. Например, для работы с SQLite можно использовать следующий код:
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# Создание базы данных и подключение к ней
engine = create_engine('sqlite:///example.db')
Base = declarative_base()
# Определение модели
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
# Создание таблиц
Base.metadata.create_all(engine)
# Создание сессии
Session = sessionmaker(bind=engine)
session = Session()Теперь можно добавлять, изменять и удалять записи в базе данных, используя объекты:
# Добавление нового пользователя
new_user = User(name='Alice', age=30)
session.add(new_user)
session.commit()
# Получение всех пользователей
users = session.query(User).all()
for user in users:
print(user.name, user.age)Django — это фреймворк для веб-разработки, который включает в себя встроенный ORM. Он позволяет разработчикам легко взаимодействовать с базой данных, используя модели, которые представляют таблицы базы данных.
Чтобы использовать Django ORM, необходимо установить Django:
pip install DjangoПосле установки можно создать проект и приложение, а затем определить модели в файле models.py:
from django.db import models
class User(models.Model):
name = models.CharField(max_length=100)
age = models.IntegerField()
# Применение миграций
# python manage.py makemigrations
# python manage.py migrateС помощью Django ORM можно легко выполнять операции с базой данных:
# Добавление нового пользователя
new_user = User(name='Bob', age=25)
new_user.save()
# Получение всех пользователей
users = User.objects.all()
for user in users:
print(user.name, user.age)Использование ORM значительно упрощает работу с базами данных, позволяя разработчикам сосредоточиться на бизнес-логике приложения, а не на написании SQL-запросов. Однако важно помнить, что ORM может не всегда быть оптимальным решением для сложных запросов, и в таких случаях может потребоваться использование чистого SQL.