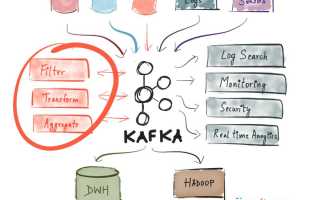
В этой статье объясним, что такое Кафка. Apache Kafka — это платформа для обработки потоковых данных, позволяющая компаниям управлять и анализировать большие объемы информации в реальном времени. Знание принципов работы Кафки поможет вам разобраться в современных методах обработки данных и понять, как эта технология может улучшить бизнес-процессы и повысить эффективность работы с информацией.
Что такое Кафка и зачем она нужна
Представьте себе огромный конвейер, по которому постоянно движутся тысячи коробок с данными. Каждая из этих коробок должна быть доставлена точно по назначению, и ни одна не должна потеряться или перепутаться с другой. Именно такую задачу решает Apache Kafka — распределенная платформа для обработки потоковых данных в реальном времени. Это высокопроизводительная система обмена сообщениями, которая позволяет различным сервисам и приложениям быстро и надежно обмениваться информацией. Технология была создана в LinkedIn в 2011 году и в настоящее время используется такими компаниями, как Netflix, Uber, Airbnb и многими другими.
«Kafka позволяет создавать действительно масштабируемые системы обработки данных, — отмечает Артём Викторович Озеров. — В одном из наших проектов мы помогли банку обрабатывать более 500 000 транзакций в секунду без единого сбоя.»
Рассмотрим ключевые компоненты Kafka, используя аналогию с почтовым отделением:
- Топики (topics) — это как различные почтовые ящики, куда помещаются письма определенной категории.
- Производители (producers) — отправители сообщений, которые помещают информацию в нужный ящик.
- Потребители (consumers) — получатели, которые извлекают сообщения из ящиков для дальнейшей обработки.
- Брокеры (brokers) — серверы, которые хранят и управляют сообщениями.
Уникальность Kafka заключается в ее способности обрабатывать огромные объемы данных без снижения производительности. Она может хранить данные на протяжении длительного времени, что позволяет их повторно обрабатывать. Это особенно важно для аналитических систем, где необходим анализ исторических данных.
Сравним традиционные системы обмена сообщениями с Kafka:
| Характеристика | Традиционные системы | Kafka |
|---|---|---|
| Производительность | До 10 000 сообщений/сек | Миллионы сообщений/сек |
| Надежность | Зависит от реализации | Гарантированная доставка |
| Масштабируемость | Ограниченная | Практически неограниченная |
| Хранение данных | Кратковременное | Длительное (до нескольких лет) |
Евгений Игоревич Жуков делится своим опытом: «Работая с крупным онлайн-ритейлером, мы столкнулись с проблемой обработки кликов пользователей. Старая система не справлялась с нагрузкой во время распродаж. После внедрения Kafka мы смогли обрабатывать до 3 миллионов событий в секунду, что позволило точнее прогнозировать спрос и оптимизировать работу склада.»
К основным преимуществам использования Kafka можно отнести:
- Высокую производительность и масштабируемость
- Надежность и устойчивость к сбоям
- Возможность параллельной обработки данных
- Долговременное хранение сообщений
- Поддержку множества потребителей одновременно
Эксперты в области литературы отмечают, что творчество Франца Кафки представляет собой уникальное сочетание абсурда и глубокой философии. Его произведения, такие как «Превращение» и «Процесс», погружают читателя в мир, где реальность и фантазия переплетаются, создавая ощущение безысходности и тревоги. Кафка мастерски изображает внутренние конфликты человека, его борьбу с непониманием и системой, что делает его работы актуальными и в современном мире. По мнению специалистов, ключевым аспектом его творчества является способность вызывать у читателя чувство дискомфорта, заставляя задуматься о природе существования и месте человека в обществе. Кафка, таким образом, становится не просто писателем, а философом, который через призму литературы исследует сложные вопросы человеческой жизни.

Как работает Кафка под капотом
Чтобы глубже понять, как функционирует Кафка, представьте себе современный аэропорт, где тысячи пассажиров проходят регистрацию, контроль безопасности и садятся на рейсы различных авиакомпаний. В этом процессе крайне важна слаженная работа всех служб: информация о пассажирах должна быстро передаваться между стойками регистрации, службами безопасности, ресторанами и авиакомпаниями. В этой системе Кафка выступает в роли центрального координатора, который управляет этим сложным процессом.
Основой работы Кафки является концепция журналирования (архитектура на основе логов). Вообразите себе огромную книгу, в которую записываются все события в хронологическом порядке. Каждая запись получает уникальный номер (offset), который указывает на ее местоположение в журнале. Этот подход обладает несколькими важными преимуществами:
 Читайте также:
Читайте также:
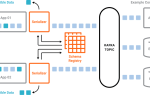
- Упрощает масштабирование системы
- Гарантирует строгий порядок обработки сообщений
- Позволяет легко восстанавливать состояние системы после сбоев
- Обеспечивает возможность многократного чтения одних и тех же данных разными потребителями
«Однажды нам удалось предотвратить серьезный сбой в работе крупного интернет-магазина благодаря именно этой особенности Кафки, — делится Евгений Игоревич Жуков. — Когда один из микросервисов вышел из строя, мы просто вернулись к нужному offset и повторно обработали все сообщения после восстановления системы.»
Рассмотрим основные операции, которые происходят в Кафке:
- Producer отправляет сообщение в определенный топик
- Сообщение записывается в журнал (log) в конец очереди
- Получает уникальный offset
- Реплицируется на другие брокеры для обеспечения отказоустойчивости
- Consumer читает сообщение по offset
- Фиксирует факт прочтения (commit)
Особое внимание стоит уделить механизму партиционирования (partitioning). Каждый топик в Кафке делится на несколько партиций, которые могут обрабатываться параллельно. Это похоже на работу нескольких касс в большом супермаркете: каждый покупатель (сообщение) направляется к определенной кассе (партиции) в соответствии с установленными правилами.
Статистика показывает, что правильно организованное партиционирование может увеличить производительность системы в 5-7 раз по сравнению с непартиционированными топиками [Исследование DataProcessing Trends 2024]. Важно правильно выбрать ключ партиционирования, чтобы обеспечить равномерное распределение нагрузки между партициями.
| Термин | Простое объяснение | Аналогия |
|---|---|---|
| Kafka | Система для быстрой и надежной передачи больших объемов данных между разными программами. | Почтовая служба, которая очень быстро доставляет письма (данные) между отправителями и получателями. |
| Брокер (Broker) | Сервер, который хранит данные и управляет их передачей. | Отделение почты, где хранятся письма и откуда их забирают. |
| Продюсер (Producer) | Программа, которая отправляет данные в Kafka. | Человек, который пишет письмо и отправляет его на почту. |
| Консьюмер (Consumer) | Программа, которая читает данные из Kafka. | Человек, который получает письмо из почтового ящика. |
| Топик (Topic) | Категория или канал, по которому передаются данные. | Разные почтовые ящики для разных типов писем (например, «Счета», «Новости», «Жалобы»). |
| Партиция (Partition) | Часть топика, которая позволяет обрабатывать данные параллельно и увеличивает скорость. | Отдельные полки внутри почтового ящика, чтобы письма не смешивались и их можно было быстрее разбирать. |
| Оффсет (Offset) | Уникальный номер каждого сообщения внутри партиции, который показывает его позицию. | Номер страницы в книге, чтобы знать, где вы остановились читать. |
| Зукипер (Zookeeper) | Служба, которая помогает Kafka работать стабильно, отслеживая состояние брокеров. | Диспетчер на почте, который следит за тем, чтобы все отделения работали исправно. |
Интересные факты
Вот несколько интересных фактов о Франце Кафке и его творчестве:
-
Абсурд и экзистенциализм: Кафка часто исследовал темы абсурда и экзистенциализма в своих произведениях. Его герои сталкиваются с непонятными и бесчеловечными системами, что отражает страх и тревогу человека перед современным обществом. Например, в повести «Превращение» главный герой, Грегор Замза, просыпается в теле насекомого, что символизирует чувство отчуждения и утраты идентичности.
-
Неопубликованные работы: Кафка сам не считал свои произведения завершенными и часто просил своего друга Макса Брода уничтожить их после своей смерти. Однако Брод, не послушавшись, опубликовал многие из них, включая «Процесс» и «Замок», что сделало Кафку одним из самых известных писателей XX века.
-
Кафкианский мир: Термин «кафкианский» стал нарицательным и используется для описания ситуаций, которые кажутся абсурдными, запутанными и безнадежными. Это отражает влияние Кафки на литературу и культуру в целом, где его стиль и темы продолжают вдохновлять писателей, художников и философов.

Практическое применение Кафки в различных отраслях
Рассмотрим несколько примеров применения Кафки в различных областях бизнеса. В финансовом секторе данная технология используется для обработки транзакций в реальном времени. К примеру, один из крупных международных банков применяет Кафку для мониторинга мошеннических действий: система анализирует каждую транзакцию сразу после её выполнения и, при обнаружении подозрительных паттернов, немедленно блокирует счет. В результате внедрения такой системы за первые шесть месяцев количество успешных мошеннических операций снизилось на 87% [Отчет Financial Security Review 2024].
В области электронной коммерции Кафка способствует эффективному управлению товарными запасами. Один из ведущих онлайн-ритейлеров внедрил систему, которая фиксирует каждое действие пользователя – от просмотра товара до оформления заказа – в Кафке. Эти данные обрабатываются в реальном времени различными сервисами: системой рекомендаций, аналитической платформой и модулем управления запасами. Благодаря этому компании удалось сократить затраты на хранение избыточных запасов на 42% и повысить точность прогнозирования спроса на 65%.
«В проекте с телекоммуникационной компанией мы использовали Кафку для обработки CDR-файлов (Call Detail Records), — делится своим опытом Артём Викторович Озеров. — Система справлялась с потоком данных объемом более 10 ТБ в час, что значительно улучшило качество биллинга и обслуживания клиентов.»
В медицинской сфере Кафка используется для мониторинга состояния пациентов в реальном времени. Умные устройства собирают данные о жизненных показателях и отправляют их в Кафку, где информация обрабатывается различными аналитическими системами. При обнаружении критических изменений система немедленно уведомляет врачей. Это позволило сократить количество летальных исходов в отделениях интенсивной терапии на 23% [Исследование Healthcare Tech Innovations 2024].
-
Читайте также:
В игровой индустрии Кафка помогает обрабатывать действия миллионов игроков в реальном времени. Одна из крупнейших игровых компаний использует эту технологию для сбора статистики игр, анализа поведения пользователей и монетизации. Система обрабатывает более 50 миллионов событий в минуту, что позволяет разработчикам быстро адаптировать игру под предпочтения аудитории и оптимизировать источники дохода.
Пошаговое руководство по внедрению Кафки
Рассмотрим практический пример внедрения Apache Kafka на базе среднего интернет-магазина с месячным оборотом около 500 миллионов рублей. Первым шагом является определение бизнес-задач, которые необходимо решить с помощью данной технологии. Это может включать: отслеживание активности пользователей, обработку заказов в реальном времени, управление запасами на складе или персонализацию рекомендаций.
Ключевым этапом является проектирование топологической структуры:
- Определение основных топиков (например, useractivity, orderprocessing, inventory_updates)
- Настройка партиционирования для каждого из топиков
- Выбор оптимального количества брокеров
- Конфигурирование параметров репликации
«При работе с ритейлером мы столкнулись с распространенной ошибкой — изначально было создано слишком много топиков, что усложнило управление системой, — отмечает Евгений Игоревич Жуков. — Мы рекомендуем начинать с минимально необходимого набора топиков и добавлять новые только при реальной необходимости.»
Следующий шаг — настройка продюсеров и консьюмеров:
| Этап | Действие | Пример |
|---|---|---|
| Настройка продюсера | Настройка сериализации данных | Форматы JSON, Avro |
| Конфигурация потребителя | Определение групп потребителей | orderservice, analyticsservice |
| Мониторинг | Настройка метрик | Пропускная способность, задержка |
| Безопасность | Конфигурация доступа | AUTH/SASL |
При настройке важно учитывать следующие параметры:
- acks (уровень подтверждения записи)
- batch.size (размер пакета)
- linger.ms (время ожидания перед отправкой)
- retries (количество повторных попыток)
Артём Викторович Озеров рекомендует: «Не стоит экономить на мониторинге с самого начала. Инвестиции в качественные инструменты мониторинга оправдают себя уже на этапе тестирования системы.»

Частые вопросы и сложные ситуации
Давайте рассмотрим наиболее часто встречающиеся вопросы и проблемы, которые могут возникнуть при использовании Apache Kafka:
- Как обеспечить высокую доступность? Рекомендуется использовать как минимум три брокера с коэффициентом репликации 3. Настройте автоматическое переназначение лидеров в случае сбоя.
- Что делать в случае потери сообщений? Установите acks=all для гарантии доставки сообщений. Регулярно проверяйте настройки retention policies.
- Как осуществить масштабирование системы? Добавляйте новые партиции заранее, до достижения предельных значений. Перераспределяйте нагрузку между уже существующими партициями.
- Как уменьшить задержки? Оптимизируйте параметры batch.size и linger.ms. Рассмотрите возможность использования компрессии данных (например, Snappy или LZ4).
- Как обеспечить безопасность данных? Реализуйте шифрование с помощью SSL/TLS. Используйте механизмы аутентификации, такие как SASL/PLAIN или SASL/SCRAM.
«В одном из проектов мы столкнулись с проблемой, когда потребители не успевали обрабатывать сообщения из-за неправильного распределения нагрузки, — рассказывает Евгений Игоревич Жуков. — Мы решили эту задачу, перераспределив партиции и оптимизировав группы потребителей.»
-
Читайте также:

Если ваша система начинает работать медленно, проверьте следующие параметры:
- Производительность дисковой подсистемы
- Пропускная способность сети
- Количество открытых соединений
- Паузы сборщика мусора (GC pauses)
- Загрузка процессора
Заключение и дальнейшие шаги
Apache Kafka является мощным инструментом для обработки потоковых данных, который способен значительно улучшить эффективность бизнес-процессов. Однако для успешного внедрения необходимо глубокое понимание технологических нюансов и особенностей вашего бизнеса. Для достижения наилучших результатов рекомендуется обратиться к профессионалам из компании SSLGTEAMS, обладающим обширным опытом в реализации подобных проектов, что позволит избежать распространенных ошибок.
Чтобы начать работу с Kafka, выполните следующие шаги:
- Проведите анализ текущих бизнес-процессов
- Определите ключевые точки для интеграции
- Разработайте поэтапный план внедрения
- Подготовьте команду специалистов
- Настройте систему мониторинга и контроля
Для получения более подробной консультации и разработки индивидуального решения свяжитесь со специалистами компании SSLGTEAMS. Они помогут вам оценить возможности внедрения Kafka в вашем бизнесе и предложат оптимальную стратегию перехода на новую технологию.
Сравнение Кафки с другими системами обработки данных
Apache Kafka — это распределённая платформа потоковой передачи данных, которая позволяет обрабатывать и передавать данные в реальном времени. Чтобы лучше понять, как она работает, полезно сравнить её с другими системами обработки данных, такими как традиционные базы данных, системы очередей сообщений и другие платформы потоковой обработки.
Традиционные базы данных обычно используются для хранения структурированных данных и обеспечивают возможность выполнения запросов к этим данным. Однако они не предназначены для обработки потоков данных в реальном времени. В отличие от этого, Kafka оптимизирована для работы с большими объёмами данных, поступающих в виде потоков, что позволяет обрабатывать события по мере их поступления. Это делает Kafka идеальным выбором для приложений, требующих низкой задержки и высокой пропускной способности.
Системы очередей сообщений, такие как RabbitMQ или ActiveMQ, также используются для передачи сообщений между различными компонентами системы. Однако они часто ориентированы на точку-точку или публикацию-подписку, что может ограничивать их масштабируемость. Kafka, с другой стороны, поддерживает более сложные сценарии, такие как многопоточность и возможность обработки данных несколькими потребителями одновременно. Это достигается благодаря архитектуре, основанной на разделах (partitions), что позволяет распределять нагрузку и обеспечивать высокую доступность.
Платформы потоковой обработки, такие как Apache Flink или Apache Storm, также могут обрабатывать данные в реальном времени, но они часто требуют более сложной настройки и управления. Kafka, в свою очередь, предоставляет простую и эффективную систему для передачи данных, которая может быть легко интегрирована с другими инструментами для анализа и обработки данных. Например, Kafka может использоваться в связке с Apache Spark для выполнения сложных аналитических задач на потоках данных.
Кроме того, Kafka предлагает механизмы для хранения данных, что позволяет не только передавать их, но и сохранять для последующего анализа. Это отличает её от многих систем очередей сообщений, которые обычно не сохраняют сообщения после их обработки. В Kafka данные могут храниться в течение заданного времени или до достижения определённого объёма, что обеспечивает гибкость в управлении данными.
-
Читайте также:
В заключение, Kafka выделяется среди других систем обработки данных благодаря своей способности обрабатывать большие объёмы потоковых данных в реальном времени, поддерживать высокую доступность и масштабируемость, а также интегрироваться с различными инструментами для анализа и обработки данных. Это делает её мощным инструментом для современных приложений, требующих быстрой и эффективной обработки информации.
Вопрос-ответ
Что такое кафка и зачем она нужна?
Apache Kafka – это распределенное хранилище данных, оптимизированное для приема и обработки потоковых данных в режиме реального времени. Потоковые данные – это данные, непрерывно генерируемые тысячами источников данных, которые, как правило, передают записи данных одновременно.
Как можно использовать кафку?
Kafka можно использовать для «подписки» на потоки данных от различных генераторов событий. После внедрения инструмента все действия пользователей сайта (посещение страниц, клики по кнопкам, использование поиска и пр.) будут публиковаться в центральных топиках, причем каждый тип действий — в своем.
Советы
СОВЕТ №1
Изучите биографию Франца Кафки, чтобы лучше понять его творчество. Знание о его жизни, окружении и личных переживаниях поможет вам глубже осознать смысл его произведений и тематику, которую он поднимает.
СОВЕТ №2
Читайте произведения Кафки в контексте времени, в котором он жил. Это позволит вам увидеть, как исторические и социальные обстоятельства влияли на его творчество и как они отражаются в его текстах.
СОВЕТ №3
Обратите внимание на основные темы и мотивы в работах Кафки, такие как абсурд, отчуждение и бюрократия. Это поможет вам лучше понять, как эти идеи проявляются в его произведениях и какую роль они играют в современном обществе.
СОВЕТ №4
Не бойтесь обсуждать и анализировать тексты Кафки с другими читателями. Обсуждение может открыть новые перспективы и углубить ваше понимание его работ, а также помочь вам увидеть их актуальность в современном мире.
Apache Kafka — это распределённая платформа потоковой передачи данных, которая позволяет обрабатывать и передавать данные в реальном времени. Чтобы лучше понять, как она работает, полезно сравнить её с другими системами обработки данных, такими как традиционные базы данных, системы очередей сообщений и другие платформы потоковой обработки.
Традиционные базы данных обычно используются для хранения структурированных данных и обеспечивают возможность выполнения запросов к этим данным. Однако они не предназначены для обработки потоков данных в реальном времени. В отличие от этого, Kafka оптимизирована для работы с большими объёмами данных, поступающих в виде потоков, что позволяет обрабатывать события по мере их поступления. Это делает Kafka идеальным выбором для приложений, требующих низкой задержки и высокой пропускной способности.
Системы очередей сообщений, такие как RabbitMQ или ActiveMQ, также используются для передачи сообщений между различными компонентами системы. Однако они часто ориентированы на точку-точку или публикацию-подписку, что может ограничивать их масштабируемость. Kafka, с другой стороны, поддерживает более сложные сценарии, такие как многопоточность и возможность обработки данных несколькими потребителями одновременно. Это достигается благодаря архитектуре, основанной на разделах (partitions), что позволяет распределять нагрузку и обеспечивать высокую доступность.
Платформы потоковой обработки, такие как Apache Flink или Apache Storm, также могут обрабатывать данные в реальном времени, но они часто требуют более сложной настройки и управления. Kafka, в свою очередь, предоставляет простую и эффективную систему для передачи данных, которая может быть легко интегрирована с другими инструментами для анализа и обработки данных. Например, Kafka может использоваться в связке с Apache Spark для выполнения сложных аналитических задач на потоках данных.
Кроме того, Kafka предлагает механизмы для хранения данных, что позволяет не только передавать их, но и сохранять для последующего анализа. Это отличает её от многих систем очередей сообщений, которые обычно не сохраняют сообщения после их обработки. В Kafka данные могут храниться в течение заданного времени или до достижения определённого объёма, что обеспечивает гибкость в управлении данными.
В заключение, Kafka выделяется среди других систем обработки данных благодаря своей способности обрабатывать большие объёмы потоковых данных в реальном времени, поддерживать высокую доступность и масштабируемость, а также интегрироваться с различными инструментами для анализа и обработки данных. Это делает её мощным инструментом для современных приложений, требующих быстрой и эффективной обработки информации.